Bluesky's source code is widely open source, so you can run your own social network with it. - Provided you stay with a comparably small user base. What's missing? A performant DataPlane implementation. Closing this gap would be an important step towards building digital independence.
We wanted to contribute our share and decided to work on a performant DataPlane for Bluesky. When we started the project, we expected to work in Go, Rust or even Node. After all, these were the predominant languages in the community. Instead, we landed with Elixir. Here is why and how we came to that decision.
The component nobody knows about
Everyone who has looked into the Bluesky infrastructure knows about the Personal Data Stores (PDS), the Relay or the AppView. When you set up your own little Bluesky from the ATProto repository, you run the same components as Bluesky, the commercial service. However, there's one notable exception: the DataPlane, a part of the AppView. It exists publicly only as a Node-and-Postgres reference implementation, while the production Bluesky network runs on a dedicated, ScyllaDB-backed, closed-source DataPlane (as documented in Pragmatic Engineer's deep-dive on Bluesky's architecture).
That gap is exactly where things get interesting. The reference implementation tells you what the DataPlane does; it doesn't tell you how to make it survive contact with real traffic.
If you want to run your own, you have to answer the scaling question yourself - and the first step is understanding the workload well enough to stop treating it as one thing.
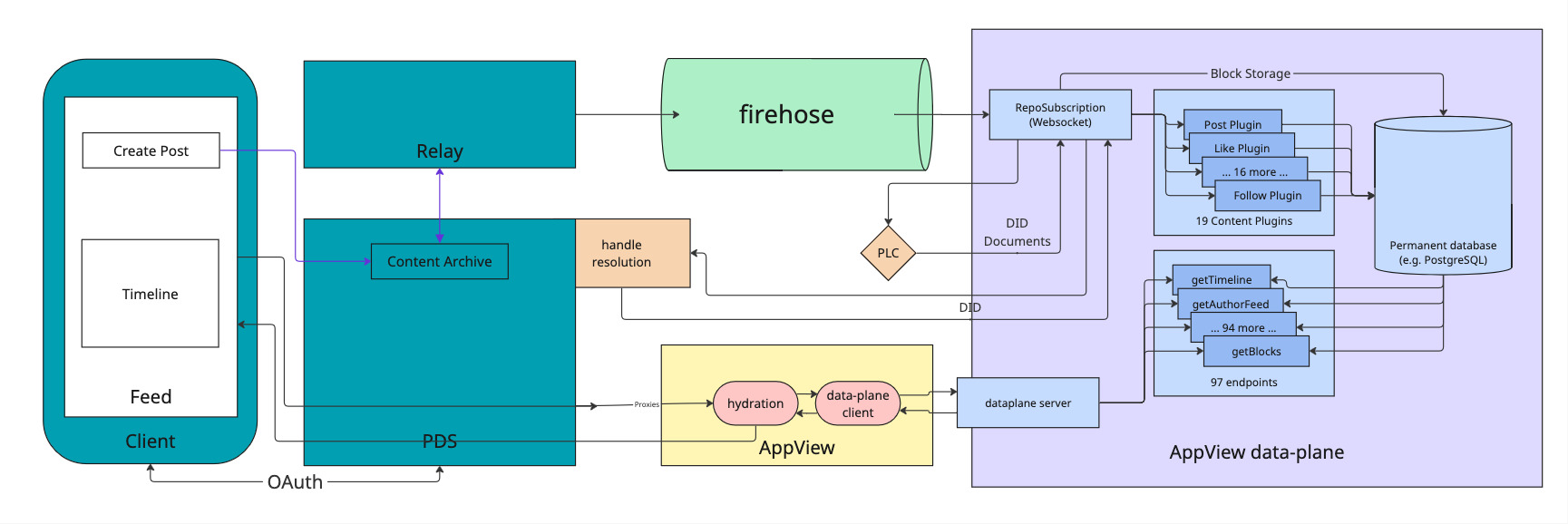
ScyllaDB is Bluesky's operational choice, not part of the interface. The DataPlane's contract is a gRPC service that answers high-volume, low-complexity queries and returns skeletons - lists of IDs, counts, booleans - which a higher layer later hydrates into full views. What sits behind that contract is entirely up to you: the language, and the datastore. So before picking either, we spent our time on the only thing that actually constrains the choice: the shape of the load.
A tale of two workloads
The Bluesky's historical data is enormous — terabytes. But when a user opens the app, they read a few dozen recent posts, get distracted, and wander off to a profile or a thread. They almost never scroll back further than a day or two.
A note on specifics: it's been observed that Bluesky's timeline doesn't serve much beyond the last day or two of content, and that deeper cursor positions tend to fill with very recent posts rather than true history. Treat the exact window as illustrative unless you've measured it on your own deployment - the architectural point holds regardless of the precise number.
This leads to an interesting disparity: Data that is more than a few days old is almost never accessed in the timeline. When it is accessed, it is usually through a profile or a thread. Yet the reference implementation compiles every timeline by joining those tables, which are terabyte-scale. This process is slow and becomes slower as the tables grow, and timeline requests account for most of what the DataPlane is asked to do.
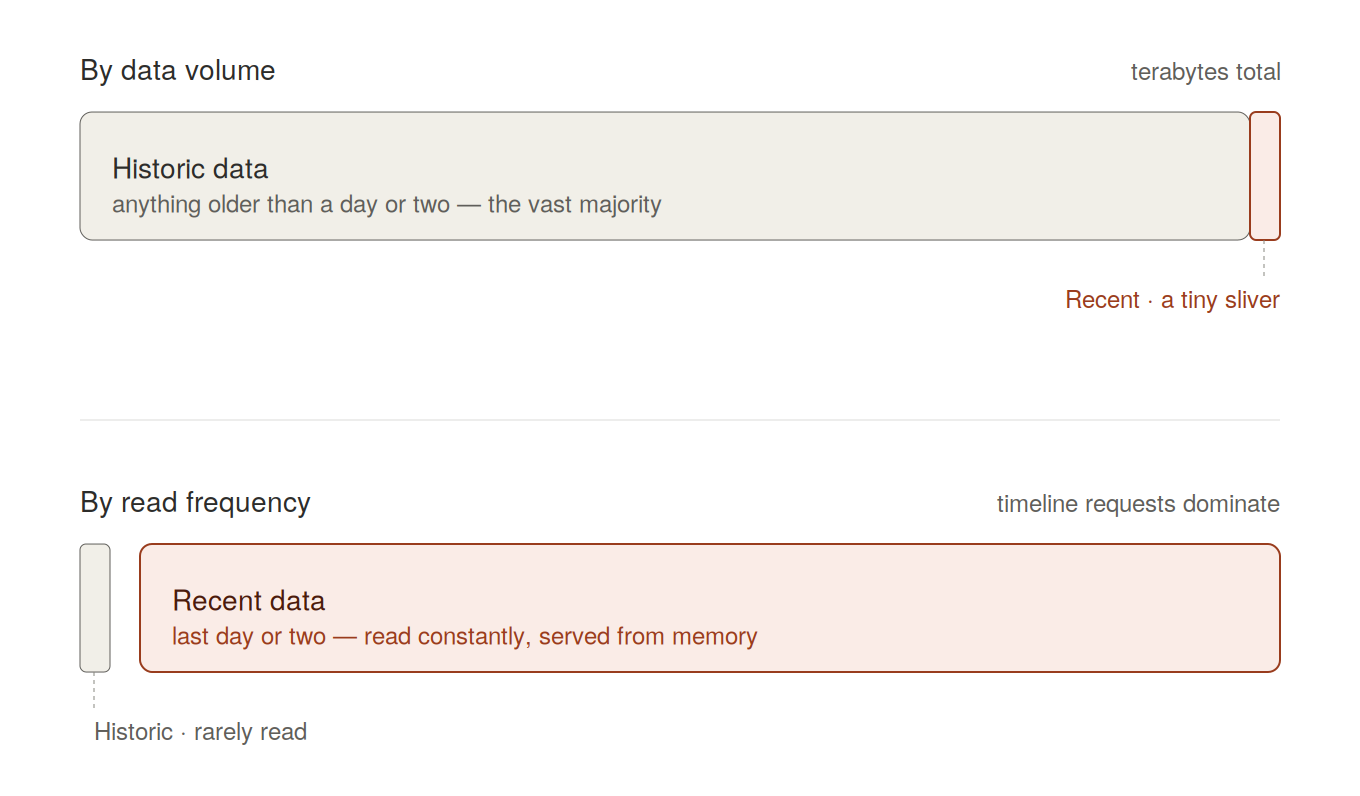
So timeline generation deserves a different treatment from record and thread retrieval. The two workloads don't just differ in degree. They have opposite resource profiles, and they want different things from the runtime underneath.
| Hot path - timelines | Cold path - records, threads, profiles | |
|---|---|---|
| Data age | Recent (last day or two) | Historic (anything older) |
| Data volume | A tiny sliver | Terabytes |
| Request share | The dominant workload | Comparatively rare |
| Bound by | Memory + compute | I/O |
| Lives in | Memory | Database, fetched on demand |
| Strategy | Fan-out + bounded timeline length | Swappable datastore behind an interface |
The hot path: timelines served from memory
Most social platforms use a hybrid strategy to handle timeline fan-out. A post from an account with a few thousand followers is pushed into its followers' timelines as soon as it is published. This is known as fan-out on write in the lingo.
However, a post from an account with millions of followers ("the celebrities") is not immediately pushed to all of its followers' mailboxes; instead, it is merged in when a follower actually requests their timeline: This is called fan-in on read. The former keeps write amplification bounded for ordinary accounts. The second prevents the write storm that a celebrity post would otherwise cause.
Another obvious simplification becomes apparent when you stop thinking of a social feed as an immutable archive. Take into account that users will jump around with their attention and you will realise that timelines are finite. Therefore, a user who follows ten thousand accounts will never see all of their posts anyway. There's reasonable to limit how much content is distributed to any single timeline. The obligation is to provide a good, recent, bounded timeline, not a complete one.
What this boils down to:
- Recent posts - the overwhelming majority of what timelines are made of - can live and be served from memory.
- Fan-out can be deferred: as long as posts land in followers' timelines within minutes, and the backlog of fan-out jobs doesn't outgrow available resources, nobody notices the delay.
- Older content, when it's genuinely needed, is safe to fetch from the database on demand.
The dominant request type, the timeline read, stops being I/O-bound (wait on a giant join) and becomes memory-and-compute-bound (manipulate in-memory structures quickly). That shift changes what "fast" means, and it's what reopened the language question for us.
It also argues for putting the concrete database behind an interface. The hot path barely touches it; the cold path is the only part that leans on it. Keep that boundary clean and you can swap the backing store later without touching the rest of the system.
The follower graph: in memory, but not naively
There's a catch. Fan-out and timeline assembly both need answers about the follow graph: who follows whom, and the intersections and unions of those sets. Holding hundreds of millions of follow relationships in memory as hash maps would be ruinously wasteful.
Jaz's "GraphD" series documents this exact problem: an in-memory graph store that originally used hash maps and hash sets to track each user's followers and follows. The fix was switching to Roaring Bitmaps, a compressed bitmap structure built for large set operations. The numbers are striking: the entire Bluesky follow graph fits in roughly 6.5 GB of RAM, takes about 1.6 GB on disk, and loads in around 20 seconds.
Jaz also describes two cost modes that map onto our hot/cold split. Paging over all of a user's follows is expensive and belongs in paginated or async fan-out jobs. On-demand set intersection — "which people I follow also follow this person" — has to run at interactive speed. Our split isn't an invention; the access patterns already worked this way in Bluesky's own tooling.
So what do we actually need from a language?
With the workload pinned down, the requirements are:
- Fast, compute-bound set operations over a large, long-lived, in-memory graph: bitmap intersections and unions. Per-core compute, byte-level work, cache sensitivity.
- High-concurrency serving of memory-resident timeline reads, with bounded response sizes and tight tail-latency expectations.
- A deferrable fan-out queue that absorbs bursts, applies backpressure, delivers within minutes, and degrades gracefully instead of falling over.
- A clean datastore boundary for the cold path: records, threads, profiles. Ordinary I/O-bound request handling.
The first three are the hot path; the fourth is the cold path. No language obviously wins all four. This is the scorecard we judged each candidate against.
The four candidates
At bitcrowd we work with Elixir, Go and Rust day to day, with the occasional Node project on the side. So this wasn't a contest between a favourite and a lineup of strangers - we had hands-on experience to weigh on every side of the comparison.
Go
Go is the incumbent. It's what Bluesky's own production DataPlane is written in, and the fit is strong. Goroutines and channels map cleanly onto "fan out work, gather results, respond." The bitmap work is comfortable in Go (GraphD itself is Go). gRPC support is first-class, deployment is a single static binary, and the tooling is mature. In-process fan-out is doable with worker pools draining buffered channels.
The costs sit at the extremes. Under heavy allocation Go's garbage collector starts eating CPU, and at very high socket counts the network backend can bottleneck on syscalls. Both respond to runtime tuning, but the tuning is ongoing work, not a one-time fix. And the in-process fan-out you build yourself comes with no supervision or isolation layer: a panicking worker takes the process down, and backpressure and lifecycle management would be our's to write.
Rust
Rust gives the highest ceiling and the tightest control. No garbage collector means no GC pauses in the tail latency. Tokio handles enormous concurrency with low per-task overhead, tonic covers gRPC, and the roaring-bitmap and datastore libraries are excellent. For the compute-bound half of our workload, nothing beats it.
The cost is velocity. As this service is thin on business logic, we would pay the price of the borrow checker and the sharp edges of async Rust on every line while protecting very little. Fan-out with Tokio tasks and channels works very well. However, as with Go, we would need to build lifecycle, backpressure and supervision manually.
Node / TypeScript
Node deserves real consideration because it's the language of the reference DataPlane and the rest of the atproto stack: PDS, AppView frontend, lexicons. One language across the codebase, shared types from lexicon definitions, the largest hiring pool, the fastest iteration. For the cold path's I/O-bound record fetches it's fine, and for modest-scale self-hosting it's a sensible default.
The hot path is where it breaks down. One event loop per process means in-memory queues and request serving compete for the same loop, and any CPU-bound work blocks both. Using multiple cores means multiple processes with no shared memory, which brings back the cross-process coordination the in-process design was meant to remove, and makes a large shared in-memory graph awkward. It's the right tool for the reference implementation and a strained one for a throughput-oriented production server.
Elixir
Elixir runs on the BEAM, a runtime built for massive numbers of cheap, isolated, preemptively scheduled processes. Per-process garbage collection means no global stop-the-world pauses, so tail latency stays flat under load. Supervision trees give fault isolation and recovery essentially for free. For high-concurrency request serving and a backpressured in-process queue, it's the most naturally suited runtime of the four.
It has one well-known weakness: raw per-core compute. The BEAM optimises for concurrency and consistent latency, not single-threaded number-crunching. Byte-level work like set operations over a large follower graph is exactly where it's slowest. Taken at face value, that rules it out for a workload with heavy bitmap operations at its core.
Every candidate has a flaw — which ones can you fix?
Four reasonable options, each with one thing standing between it and a clean fit. Instead of arguing it on paper, we prototyped toward each remedy, far enough to tell whether the flaw could be engineered away or was structural.
Go's GC and syscall overheads respond to tuning, and Bluesky's production DataPlane proves you can push Go a long way. But the tuning never ends. It's a knob you keep turning for the life of the service.
Node's single event loop has exactly one fix, running more processes, and that fix recreates the cross-process coordination and shared-state problems we were designing out. There's no way around it within the language.
Rust has no performance flaw. Its cost showed up as soon as we started building: hand-rolled concurrency, lifecycle and backpressure machinery on every path, for a service with little logic to protect. We realised that that cost would not shrink over time, but stay with us with every change we would need to make.
Elixir's flaw, per-core compute on tight loops, is real, and we hit it where you'd expect: the follower-graph set operations. But it stayed in one place. It didn't smear across the service. It sat in a single, well-defined component we could draw a boundary around, and a component with a sharp boundary can be replaced. That's what sent us back to Elixir for a second look.
Resolving the Elixir paradox
Can that component actually be lifted out? Yes, and the reason has less to do with Elixir than with how our system is laid out.
Start with the claim itself, because it's often stated too broadly. "The BEAM is slow at CPU work" is true for tight numeric loops on a single core. It is not a claim about how much hardware a real service needs. Most of what a production server spends its time on isn't a tight loop; it's keeping thousands of concurrent requests moving, and the BEAM is efficient at exactly that.
Per-process garbage collection means no global pauses, and tail latency stays flat enough that you can run a node closer to its limit and still hit your latency target.
This is why Elixir services often need fewer machines than the Go or Node version of the same thing, occasionally approaching Rust, even though they lose every microbenchmark. Hardware cost under concurrency and single-core throughput are two different measurements, and only one of them shows up on your bill.
That said, our workload really does contain the thing the BEAM is bad at: the roaring-bitmap intersections and unions over the follow graph. We don't want to talk our way around that, so we move it off the BEAM entirely.
The follower graph lives in a Rust implementation of Roaring Bitmaps, called from Elixir as a NIF (Native Implemented Function). What makes this more than a generic "wrap the slow part in Rust" patch is the shape of the data flow:
- The input crossing the boundary is tiny: a user ID, or a small set of IDs.
- The graph itself, millions of edges, stays on the Rust side in native memory. The BEAM never holds it, never copies it, never garbage-collects it.
- The expensive compute, the intersections and unions, runs entirely inside Rust at native speed.
- Only the result crosses back, and because timelines are length-limited, that result is small by construction.
The usual objection to NIFs is the copy cost at the boundary. But in our case, only small data crosses in both directions while the big structure and the heavy computation stay native, which is the ideal case. That isn't luck. The timeline-length limit we'd already committed to is what bounds the return values.
This subtracts the BEAM's weakness from the hot path and keeps its strengths. The compute-bound half runs in Rust regardless of host language. What's left for Elixir is orchestration: high-concurrency request serving and the fan-out queue, the regime where the BEAM is at its best and where our own production experience says it's most efficient.
Of course, the NIF has its own price. It runs inside the BEAM's memory space, so a crash in the Rust code can take down the VM, and a long-running call can stall a scheduler. So we give up some of the "let it crash" isolation exactly at the native boundary. The mitigations fit this case well: the calls are short (small in, bounded compute, small out), and the Rust surface is small, stable, and the kind of code that rarely changes once written. Two languages is a real maintenance cost, but Rustler keeps the boundary ergonomic, and a small, bounded Rust core seemed the cheapest of the available evils.
The deciding factor: fan-out as code, not infrastructure
The NIF made Elixir competitive. The fan-out requirement made it the choice.
Recall the spec: a deferrable queue that absorbs bursts, applies backpressure, delivers within minutes, and degrades gracefully when the backlog grows. In Go, Rust or Node, that almost always becomes an external system — Redis, NATS, RabbitMQ, Kafka — because the language doesn't give you primitives to do it safely in-process.
On the BEAM, those primitives are the language. Processes are the workers, mailboxes are the queues, supervisors handle recovery, and GenStage and Broadway add explicit backpressure, all inside one VM with no network hop and nothing extra to deploy. Several costs disappear outright:
- No serialisation across a queue boundary. An external queue serialises every fan-out job on push and deserialises it on pop, putting per-event encoding cost right back on the hot path we'd worked to keep it off. In-process, a job is a message between processes.
- No second system to operate. No separate scaling story, no "is Redis the bottleneck now," no disagreement between the service's view of the backlog and the queue's.
- One failure model. Supervision covers fan-out workers the same way it covers everything else. There's no seam between "the service crashed" and "the queue is in a weird state."
- Backpressure in-band. Producer and consumer share a runtime, so the producer notices the consumer falling behind directly instead of inferring it from queue-depth metrics after the fact.
The trade is durability. In-process means in-memory, and an in-memory backlog dies with the node. For us that's acceptable: fan-out is best-effort timeline population, timelines are bounded and ageing, and the fan-in path on read covers whatever goes missing for a window. We're choosing fast, simple and lossy-on-crash over durable, external and heavier, and the choice only works because the rest of the architecture makes the loss cheap. If you need durability here, much of the in-process advantage narrows. Check this assumption against your own tolerances.
Why Elixir
We love working with Elixir, but we did not assume it to be the tool of choice for this project. The ecosystem just did not seem to be waiting for it. Choosing it means making the case for it, repeatedly, starting with this post.
And Elixir doesn't win every category. We came to the decision to use it because, for this specific workload, the one axis it loses on — per-core compute for graph operations — is the one we can cleanly offload to a small Rust NIF, with a data flow that makes the offload nearly free.
Everything that remains is concurrency, coordination, predictable tail latency under load, and a burst-absorbing fan-out queue we can build in the program itself instead of bolting on as infrastructure. Go would have been the pragmatic, proven middle.
Rust would have given us the highest ceiling at the cost of velocity and a lot of hand-rolled concurrency machinery. Node was right for the reference implementation and wrong for a memory-bound production server. Elixir plus a thin Rust core covers both halves of a workload that genuinely has two halves.
What next?
Most of this is architecture-level reasoning informed by the workload's shape and each runtime's known characteristics. We backed this up with head-to-head benchmarks between the Node reference implementation and our Elixir POC.
For that, we needed to build a performance evaluation toolkit for our studies. If you want to find out the limits of your setup, check it out
The pieces we lean on hardest are well-sourced: Jaz's GraphD work for the in-memory graph and Roaring Bitmaps, and the documented existence of a fan-in/fan-out split between expensive paging and interactive-speed set intersection. The pieces we're least certain about - the exact timeline window, the precise per-request CPU breakdown - we've flagged as such.
We have build and tested a proof of concept that serves the skeleton amazingly fast. What is missing now is the boring part of writing the > 90 endpoints of the DataPlane API and the indexer plugins. Currently, it's a side project. Give us a shout if you want to help us take it further, faster.
