Recently, we presented our performance toolkit for atproto including a small Proof-of-Concept for a dataplane written in Elixir. We didn't go too much into the details though. We will make up for that in this post.
Let's start by recapping the problem.
The AT Protocol enables us to build an open social ecosystem of interoperable applications. By far the most popular application in this ecosystem today is Bluesky.
Bluesky has open sourced almost all of their software. You can find their app, their Go services and their TypeScript code (backend services and protocol reference implementation).
This is their production code, with one exception: they don't run the open source dataplane. They've replaced it with a closed source implementation that is more performant.
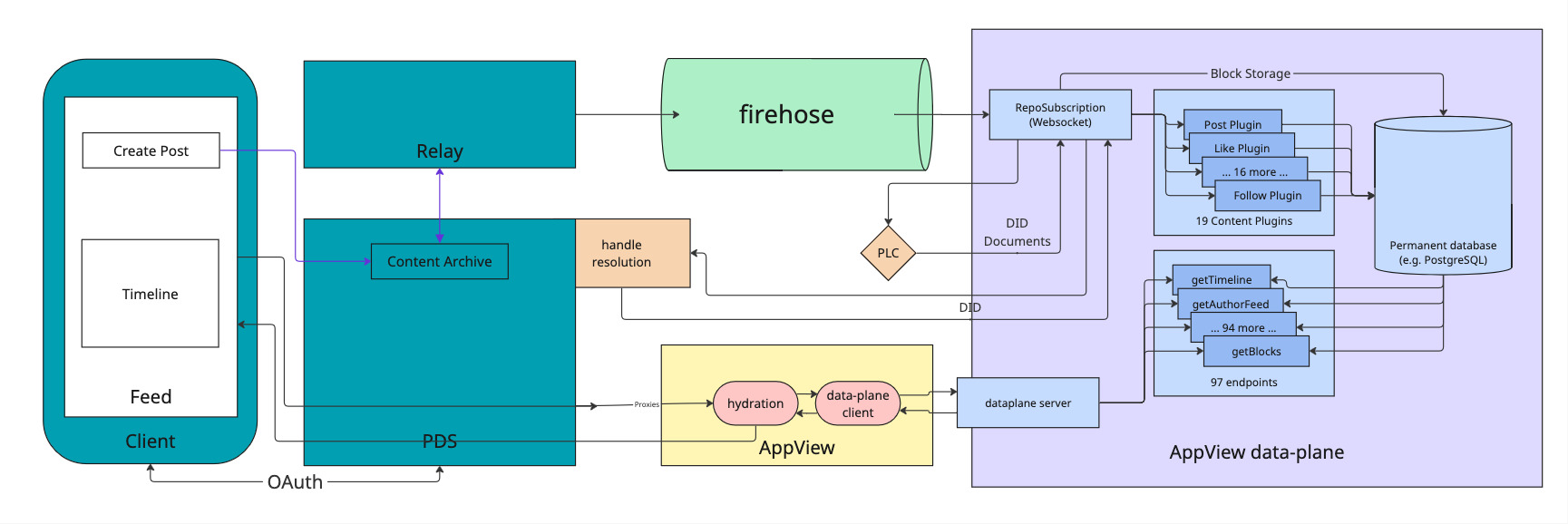
We talked about some of the issues of the open source dataplane in our previous blog post.
The bottom line is: it won't scale if you're trying to serve hundreds of thousands of users.
Why you should care
Even the Bluesky people think that hard decentralization is necessary. What is the point of an open ecosystem when everything is tied to the existence of a single company?
- Bluesky can be bought and start to enshittify
- Bluesky operates under US law, why should we want our online social life to be ruled by mad people inside a white house
- Bluesky has outages, alternatives could continue to operate
So, we should want alternative providers of Bluesky to exist.
Luckily for us, there is already a number of organizations picking up that work.
Luckily for them, they can build on the open source components that Bluesky provides.
Unluckily for them, they are left with a dataplane implementation that won't work for them when their userbase grows.
As a result, the Blacksky people have to spend their time rewriting components in Rust and our friends from Eurosky started exploring alternative ways to build timelines.
Serving timelines from Elixir
Elixir provides a number of benefits for a backend service like the dataplane.
You work on a high level of abstraction, getting more done in the same amount of time and end up with very readable code (yes, this is still important, even for your agent!).
At the same time you get parallelism for free and performance that scales with the cores of the system.
Errors are isolated, so they don't bring down the whole service.
As a bonus, the VM provides you with good tooling for introspection and observability, all out of the box.
So, when we built our Proof-of-Concept, we naturally chose Elixir. For the full reasoning behind that decision (why Elixir over Go, Rust and Node), see our companion post. We wanted to investigate the performance issues that will come up in the open source dataplane implementation. For this reason, we focused on implementing the critical endpoint which is responsible for serving timelines to users.
From our exploration in the last blog post, we already know that the most important decision to solve the issues of Bluesky's open source database implementation is to change the approach from fan-in to fan-out.
When a user requests their timeline from Bluesky's open source database implementation it will query the posts that should be in the timeline on demand. This is known as fan-in principle and is a major reason for the performance issues of this implementation.
Consequently, the implementation used by Bluesky in production turns this process on the head, known as the fan-out principle. It constructs the timeline for each user whenever a new post arrives in the system. When the user requests their timeline, the data is already waiting for them to be served.
ETS tables
With this insight, it was clear to us that we should build our dataplane on the fan-out principle. It was less clear how we should store the data we need. The Erlang VM has multiple built-in options for storing data, so choosing one of them, the Erlang Term Storage (ETS), was a good starting point.
Citing the documentation:
Data is organized as a set of dynamic tables, which can store tuples.
...
Tables are divided into four different types, set, ordered_set, bag, and duplicate_bag. A set or ordered_set table can only have one object associated with each key. A bag or duplicate_bag table can have many objects associated with each key.
ETS stores data as tuples in tables in memory but which tables do we need to store all the data we need to serve timelines? And of which type should the tables be?
To store follows in a way that we can retrieve all the information we need efficiently, we actually need two tables: followers_table and following_table.
:ets.new(@followers_table, [
:duplicate_bag,
:named_table,
:public,
read_concurrency: true,
write_concurrency: true
])
:ets.new(@following_table, [
:duplicate_bag,
:named_table,
:public,
read_concurrency: true,
write_concurrency: true
])
These store the follows information in both directions, holding pairs of user IDs.
We can find all the followers of a user by looking up the entries with their user ID as key in the followers_table.
And we can find all the users this user follows by looking up the entries with their user ID as key in the following_table.
Both tables are of type :duplicate_bag.
We need multiple entries per key, so we must use either :bag or :duplicate_bag as type of the table.
:bag would have the benefit of preventing duplicates, however we chose :duplicate_bag for its performance benefits.
The posts_table represents the source of truth for all the posts in the system.
It's a :set storing post IDs as we don't want duplicates here.
:ets.new(@posts_table, [
:set,
:named_table,
:public,
read_concurrency: true,
write_concurrency: true,
decentralized_counters: true
])
In the feeds_table we store the feeds of all users.
:ets.new(@feeds_table, [
:duplicate_bag,
:named_table,
:public,
read_concurrency: true,
write_concurrency: true,
decentralized_counters: true
])
Whenever a new post arrives in our system, we look up all the followers of the author of the post using the followers_table.
Then, for each follower we store a pair of the follower's user ID and the post ID in the feeds_table.
We chose the type :duplicate_bag here for the same reasons as we did for the followers_table.
We need multiple entries per key (user ID) and we want the performance benefits of :duplicate_bag over :bag.
Celebrities
With these tables we would have a functioning system.
However, there is still the celebrity_posts_table to talk about.
:ets.new(@celebrity_posts_table, [
:duplicate_bag,
:named_table,
:public,
read_concurrency: true,
write_concurrency: true,
decentralized_counters: true
])
This table is actually a first optimization of the system.
You might have wondered what would happen if a post arrives in the system authored by a user who has many many followers.
If we would stick to our feeds_table, we would have to loop through all of them to insert the corresponding data.
For this reason, we introduced the celebrity_posts_table.
The key idea here is that if a user has too many followers (is a celebrity), we give their posts a special treatment to avoid looping through all the followers and the associated performance issues.
Instead we will store pairs of the author and post IDs in celebrity_posts_table, which is again of type :duplicate_bag.
def insert_post(post_id, author_id) do
:ets.insert(@posts_table, {post_id, author_id})
follower_entries = :ets.lookup(@followers_table, author_id)
limit = fan_out_limit()
if limit == :infinity or length(follower_entries) <= limit do
Enum.each(follower_entries, fn {_subject, follower_id} ->
:ets.insert(@feeds_table, {follower_id, post_id})
end)
else
:ets.insert(@celebrity_posts_table, {author_id, post_id})
end
end
When a user request their timeline, we will first look for their feed in the feeds_table, then do another lookup in the celebrity_posts_table to gather posts from celebrities they follow.
The user will then see a combination of those posts.
So, in fact this dataplane combines fan-out (for regular posts in feeds_table) with fan-in (for celebrity posts in celebrity_posts_table) for performance reasons.
def get_timeline(user_id) do
fan_out_posts =
@feeds_table
|> :ets.lookup(user_id)
|> Enum.map(&elem(&1, 1))
celebrity_posts =
@following_table
|> :ets.lookup(user_id)
|> Enum.flat_map(fn {_actor, followed_id} ->
:ets.lookup(@celebrity_posts_table, followed_id)
end)
|> Enum.map(&elem(&1, 1))
fan_out_posts ++ celebrity_posts
end
Evaluating our dataplane
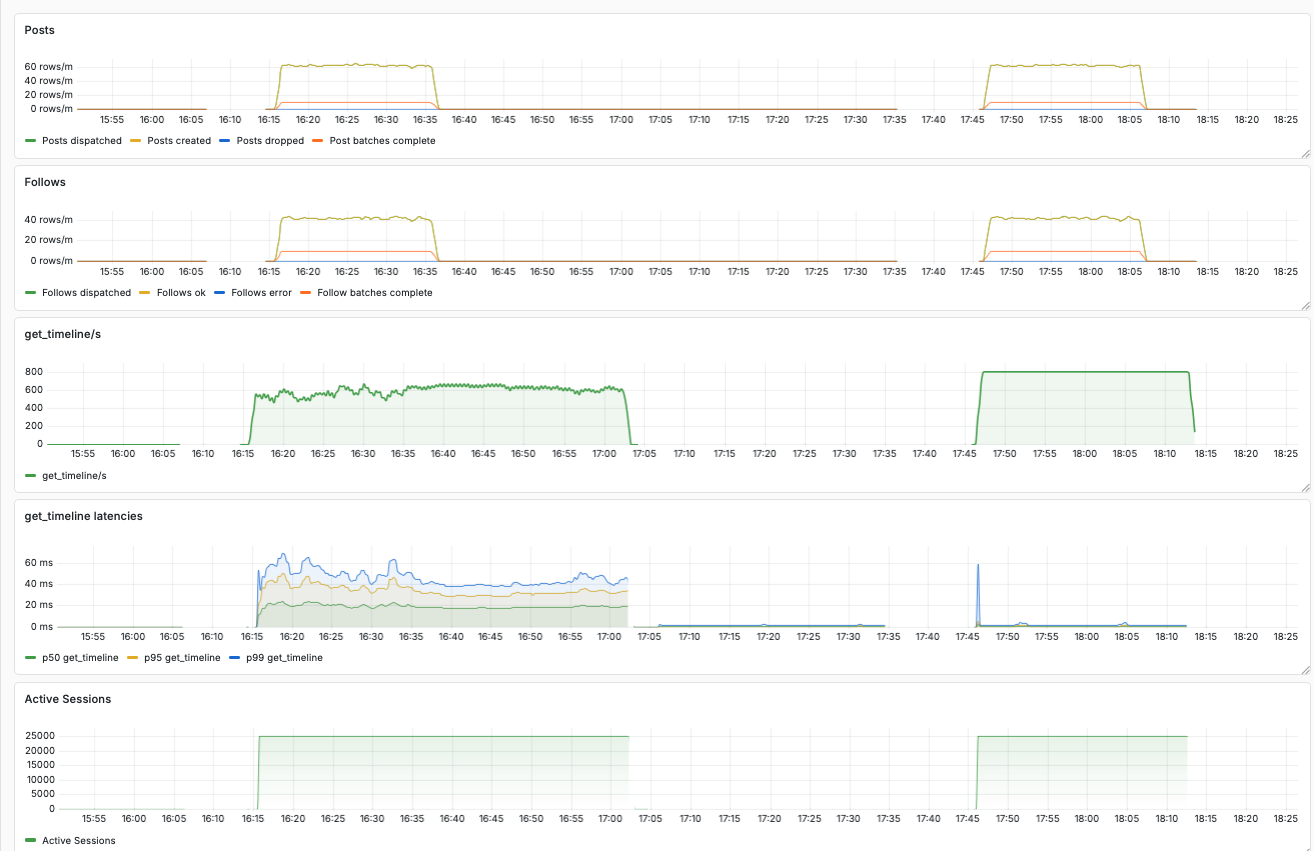
To get an idea about how much performance we gain with our dataplane, we evaluated it using our simulator. The dashboard below shows the results of this comparison.
We can see two blocks of data:
The first run was recorded with Bluesky's open source dataplane. We can see a maximum p99 latency of more than 60 ms. Furthermore, we see the throughput of requests per second fluctuating around 600.
In comparison, the block on the right shows recordings of the same simulation with our dataplane. The latencies are tiny, the throughput sits smoothly at 800 requests per second.
Crimeline comparison
Crimeline is an experimental timeline builder which caught our attention when doing research for this project.
Like our proof of concept, Crimeline is not a complete dataplane implementation.
Unlike our proof of concept, Crimeline focuses on creating efficient datastructures and conveniently comes with synthetic benchmarks for them.
After having seen the end-to-end evaluation of our dataplane, we were curious how ETS tables would perform in those benchmarks.
The README describes one of Crimeline's datastructures, the UserMap, as follows:
Sharded adjacency map. Each uid is split via bitmask into shard index (low bits) and backbone index (high bits). Each shard holds a
Vec<Vec<Uid>>— a dense backbone of sorted adjacency lists.
It's a struct that holds information whether a user ID is included in it (think your followers on Bluesky) with efficient methods to add and remove user IDs as well as performing the lookup of an ID.
An ETS-based equivalent looks like this:
defmodule UserMapEts do
@user 0
def new do
:ets.new(:forward, [:duplicate_bag, :public, {:read_concurrency, true}])
end
def populated(n) do
table = new()
tuples = for t <- 0..(n - 1), do: {@user, t * 3}
:ets.insert(table, tuples)
table
end
def add(table, target) do
:ets.insert(table, {@user, target})
end
def add_bulk_list(table, targets) do
tuples = for t <- targets, do: {@user, t}
:ets.insert(table, tuples)
end
def add_bulk_each(table, targets) do
Enum.each(targets, fn t -> :ets.insert(table, {@user, t}) end)
end
def contains(table, target) do
:ets.match_object(table, {@user, target}) != []
end
def remove(table, target) do
:ets.delete_object(table, {@user, target})
end
def destroy(table) do
:ets.delete(table)
end
end
We can expect this to be a bit slower than the Rust implementation of Crimeline due to the overhead of the Erlang VM.
The table below shows the average time for each operation in nanoseconds when performed with 100 users.
From our results, we can see that ETS tables nevertheless perform relatively well.
| Operation | Rust UserMap | ETS UserMap |
|---|---|---|
| add | 18 ns | 186 ns |
| contains_hit | 8 ns | 1360 ns |
| contains_miss | 8 ns | 1350 ns |
| remove | 26 ns | 599 ns |
So overall we were happy but two benchmarks stood out with growing numbers of users: contains_hit and contains_miss.
Note the units in the following table.
While the Rust UserMap goes from 8 ns to 14 ns (not even 2x) when increasing the number of users from 100 to 100_000, ETS goes from 1.36 μs to 1.11 ms, almost 1000x.
| Operation (number of users) | Rust UserMap | ETS UserMap |
|---|---|---|
| contains_hit (100) | 8 ns | 1.36 μs |
| contains_hit (100_000) | 14 ns | 1.11 ms |
| contains_miss (100) | 8 ns | 1.35 μs |
| contains_miss (100_000) | 14 ns | 1.11 ms |
Why is this so slow? From the ETS docs:
Insert and lookup times in tables of type set are constant, regardless of the table size. For table types bag and duplicate_bag time is proportional to the number of objects with the same key.
We chose a :duplicate_bag for the table to improve insert performance.
Now we are paying for that with slow lookups at scale.
Roaring Bitmaps
We didn't give up here, of course. So let's see what we can improve.
During our research, we also came across Jaz's blog and learned how to shrink the size of your datastructures and go even further with Roaring Bitmaps. The latter seems to be a good fit for optimizing our user map datastructure.
Luckily, rustler lowers the barrier to use Rust crates from Elixir a lot these days. Conveniently for us, Aaron Gunderson already did the work to wrap the roaring crate in an Elixir package and blogged about it. So, it's ready for us to use.
As a very brief summary, bitmaps are a suitable datastructure to compress the follower graph in our dataplane.
Instead of storing pairs of {user_id, follower_id}, we store a single array for each user where each bit represents whether the user with the id at the index follows the user.
Say we have 5 users, and our ids start at 0. If the first four users all follow user with id 4, we would store the following pairs in our ETS table:
# user_id, follower_id
{4, 0}
{4, 1}
{4, 2}
{4, 3}
With a bitmap, we would store a single array of bits for the user with id 4.
If the bit is 1, the corresponding user follows the user with id 4.
# user_id/index:
# 0, 1, 2, 3, 4
[1, 1, 1, 1, 0]
You can see how that compresses the required space in memory in this simplified example.
Assuming 1 byte per id, we would have 4 * 2 = 8 bytes of memory in our ETS table variant.
The bitmap however is complete with 5 bits which fit in a single byte.
Roaring bitmaps apply further optimizations on top of this basic idea.
With the roaring package we can plug the Roaring Bitmap into our user map module.
defmodule UserMapRoaring do
def new do
{:ok, roaring} = RoaringBitmap64.new()
roaring
end
def populated(n) do
list = for t <- 0..(n - 1), do: t
{:ok, roaring} = RoaringBitmap64.from_list(list)
roaring
end
def add(roaring, target) do
RoaringBitmap64.insert(roaring, target)
end
def add_bulk_list(roaring, targets) do
for t <- targets, do: RoaringBitmap64.insert(roaring, t)
end
def add_bulk_each(roaring, targets) do
Enum.each(targets, fn t -> RoaringBitmap64.insert(roaring, t) end)
end
def contains(roaring, target) do
RoaringBitmap64.contains?(roaring, target)
end
def remove(roaring, target) do
RoaringBitmap64.remove(roaring, target)
end
def destroy(_roaring) do
:ok
end
end
With that we get the following results.
| Operation (number of users) | Rust UserMap | ETS UserMap | Roaring Bitmaps UserMap |
|---|---|---|---|
| contains_hit (100) | 8 ns | 1.36 μs | 104 ns |
| contains_hit (100_000) | 14 ns | 1.11 ms | 100 ns |
| contains_miss (100) | 8 ns | 1.35 μs | 98 ns |
| contains_miss (100_000) | 14 ns | 1.11 ms | 100 ns |
We're still slower than Crimeline's implementation but it's acceptable and more importantly does not degrade with the number of users.
Comparison in a more realistic scenario
After satisfying our curiosity about Crimeline's synthetic benchmarks, we were wondering how the comparison would look like in a more realistic scenario.
Therefore, we added another benchmark feeds that is somewhere in between Crimeline's benchmarks and the work we've previously done with our simulator.
Interestingly, in this more realistic scenario the performance difference between the implementations diminishes.
| Operation (number of follows) | Rust feed | ETS feed | Roaring Bitmaps feed |
|---|---|---|---|
| get_feed (100) | 41 µs | 9 μs | 8 μs |
| get_feed (100_000) | 57 µs | 117 μs | 108 μs |
| get_feed (1_000_000) | 58 µs | 118 μs | 109 μs |
Where to go from here?
We showed how to build a basic dataplane implementation in Elixir, then added optimizations to squeeze out the issues we encountered.
One essential feature that is missing from our implementation is persistence. So far we store everything in memory, so our data wouldn't survive a restart of the server.
Our goal is to provide a simple to use dataplane implementation. So, the first idea would be to add persistence with Postgres and treat our in-memory data as an index to avoid costly queries and retrieve the data directly by primary key. Another idea is to provide an adapter interface so that everyone can use their preferred database.
We've seen how to combine Rust and Elixir to get the strengths of both while mitigating their weaknesses (Discord has a great write-up on the same idea). We dig into why this pairing fits a dataplane so well in our companion post; here the takeaway is practical. We can optimize the hot spots in Rust, confident the native code won't crash the VM thanks to Rust's memory-safety guarantees, while keeping the readable, high-velocity Elixir everywhere else. Whether it's Roaring Bitmaps or even wrapping the Crimeline datastructures, a whole ecosystem of crates is available to us.
With that, we have all the tools to build the remaining features a complete dataplane implementation needs and we are ready to add more advanced features like the social proof that is available in Bluesky.
