Where we left off
In our last post Full Text Search in the Age of MCP, we saw
how full-text search struggles with long, natural-language queries typical for MCP systems. PostgreSQL’s
plainto_tsquery was a good start but broke down when faced with verbose inputs. We combined techniques—trigram
matching, semantic search with embeddings, and hybrid strategies—to restore relevance. That gave us a system that
worked, but it left an important question open: how do we know it really works?
This post is about building the tools to answer that question.
Datasets
It's common to call the set of documents in a search system corpus. In many AI use cases, such as RAG, agents or MCP servers, this corpus is organised in smaller document fragments, called chunks. If you want to evaluate how well a search system works on a certain corpus, you need test data.
Often the test data is comprised of pairs of questions and result_sets. The result_sets are sets chunks from your corpus that are relevant to the question.
Without a dataset, we’re just guessing. With one, you can measure, compare, and improve. Let's create a dataset of good questions.
So, what is a good question?
For our dataset, a good question is one that can only be answered with the help of the documents from that corpus. Moreover, a good question should be so specific that only a small number of chunks provide the needed information.
If we provide those relevant pieces of content as context to the question, an answer should be matching the facts from the context much better than without providing the context.
A good question should also reflect a common need ("use case") users have towards our system. Our example is a RAG system that is operating on package documentation. So use-cases might be:
- A user has a specific problem with a package ("I keep getting an error ...")
- A user needs to decide if a package is fitting their need, so they make inquiries about a system. ("What does package x do?)
Three examples
- “Why does
Req.get!("…", into: :self)fail with anArchiveErrorwhen trying to decode a response body?“
- This question is specific to our corpus
- It also gives an llm no hint to come up with an uninformed right solution.
- “Why do I encounter
Req.ChecksumMismatchErrorwhen using `Req.Steps.checksum/1”
- This question is also specific to our corpus
- But it gives an llm a good hint (by the naming) to hallucinate a correct solution
- “Why is the sky blue” This is the worst of both categories:
- The question is not relevant to our corpus
- It's also already in every llm's training data
Questions that the LLM might know an answer to are problematic because they give us the impression that search / retrieval is working correctly, while in fact, it's not. Therefore, we should be careful to test retrieval and generation in separation.
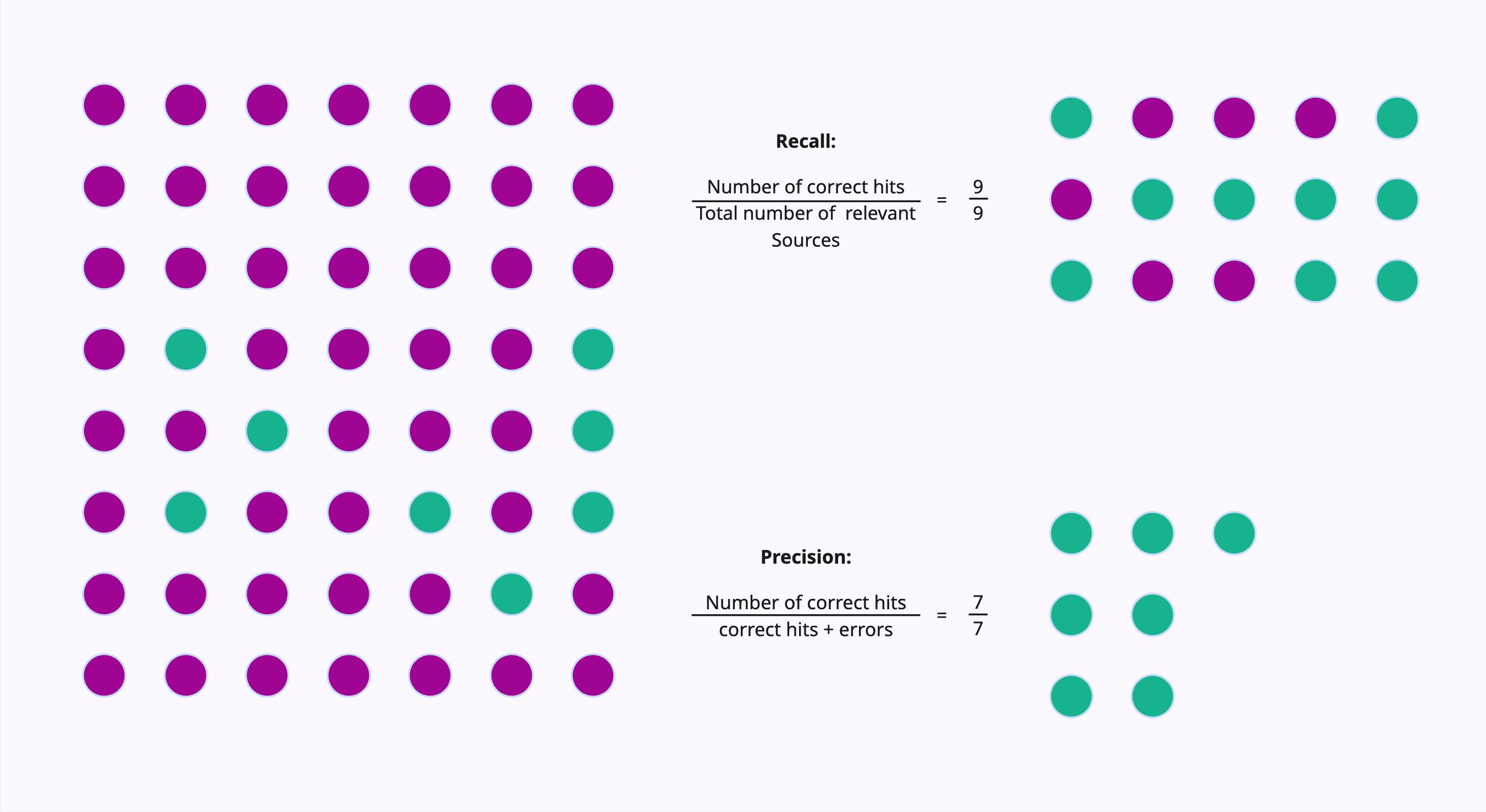
Classic Evaluation Metrics
If you have gotten your feet wet in Machine Learning already, you will surely have come across the following metrics. They are the most common KPI in classification tasks.
In short:
- Precision: Of the returned results, how many were relevant?
- Recall: Of all relevant results in the corpus, how many did we return?
In many cases, you can not achieve perfection in both metrics. You either accept miss some of the relevant documents, or you accept noise in your dataset.
Synthetic Questions
In our last post, , we left off with a set of generated questions. The idea was that, if we tell an llm to come up with questions that match a certain chunk, it might come up with a question that we at least know one correct document chunk for.
Let's have a look at one of them:
%{
%{
source: "lib/req/steps.ex",
question: "How do you disable automatic response redirects in a request using `Req`?",
content: "# lib/req/steps.ex\n\nThe original request method may be changed to GET depending on the status code:\n\n | Code | Method handling |\n | ------------- | ------------------ |\n | 301, 302, 303 | Changed to GET |\n | 307, 308 | Method not changed |\n\n ## Request Options\n\n * `:redirect` - if set to `false`, disables automatic response redirects.\n Defaults to `true`.\n\n * `:redirect_trusted` - by default, authorization credentials are only sent\n on redirects with the same host, scheme and port. If `:redirect_trusted` is set\n to `true`, credentials will be sent to any host.\n\n * `:redirect_log_level` - the log level to emit redirect logs at. Can also be set\n to `false` to disable logging these messages. Defaults to `:debug`.\n\n * `:max_redirects` - the maximum number of redirects, defaults to `10`. If the\n limit is reached, the pipeline is halted and a `Req.TooManyRedirectsError`\n exception is " <> ...,
chunk_id: "3e4a72db-fced-4634-9b4f-209a07f41c80"
}
As a recap: We used chunk "3e4a72db-fced-4634-9b4f-209a07f41c80" to generate a the question "How do you disable
automatic response redirects in a request using Req?". We assume that our generated question is good enough to yield
chunk "3e4a72db-fced-4634-9b4f-209a07f41c80" in the result sets of the search functions.
We can use as early performance indicators:
- Is chunk "3e4a72db-fced-4634-9b4f-209a07f41c80" found in the result set?
- Is chunk "3e4a72db-fced-4634-9b4f-209a07f41c80" the highest ranking hit?
- At what rank does chunk "3e4a72db-fced-4634-9b4f-209a07f41c80" appear in the list of matches?
- How many other hits are there?
Let's have a look:
%{
source: "lib/req/steps.ex",
question: "How do you disable automatic response redirects in a request using `Req`?",
results: [
jina_v2_code: %{
chunk_was_found: true,
first_hit_correct?: false,
total_chunks_found: 114,
chunk_position: 12
},
all_minilm_l6_v2: %{
chunk_was_found: true,
first_hit_correct?: false,
total_chunks_found: 114,
chunk_position: 25
},
nomic_embed_text: %{
chunk_was_found: true,
first_hit_correct?: false,
total_chunks_found: 114,
chunk_position: 25
},
mxbai_embed_large: %{
chunk_was_found: true,
first_hit_correct?: true,
total_chunks_found: 114,
chunk_position: 1
},
pg_fts: %{
chunk_was_found: true,
first_hit_correct?: true,
total_chunks_found: 89,
chunk_position: 1
},
pg_tgrm: %{
chunk_was_found: true,
first_hit_correct?: false,
total_chunks_found: 70,
chunk_position: 21
}
],
These results have to be taken with a lot of salt:
-
Because of the way we generated the questions, we can not rule out that there are more matching sources then our starting point chunk, "3e4a72db-fced-4634-9b4f-209a07f41c80". They might even be more fitting to our question. So, a rank of 25 does not necessarily mean our search is broken. A good question should have few matches, but it might also be very artificial, which comes with it's own challenges.
-
We have way to many search results. All search functions are currently operating with much too high thresholds.
Bootstrapping
We now have a high level of uncertainty. Our Questions are generated by AI. Anything can be in there. Also, our result set comes from - so far - experimental sources. How can we consolidate our dataset?
Maybe we can build on this:
Our question make it somehow easy for the search functions. Can we use that circumstance?
-
Common ground: If chunks appear in all searches, can we assume that they have high relevance? Can we assume that hits that only appear with single search functions are noise?
-
Common ranks: If we apply mechanisms like reciprocal rank fusion to the result set, can we use membership in the "top ten of those lists as indicator for "a save bet"?
** Work in progress **
This blog post is work in progress. Come back in the next few days to discover how we move from uncertainty to a more solid result set.
Conclusion
Search isn’t finished when it works. It’s finished when you can prove it works—and refine it when it doesn’t.
By generating datasets, asking the right questions, and measuring with precision and recall, we turn search from a black box into an iterative, improvable system.
The Age of Refinement is about this loop: evaluate, improve, repeat.
Elixir is an excellent choice for applications due to its scalability, fault tolerance, and concurrency model. Its lightweight processes and message-passing architecture make it ideal for orchestrating complex AI workflows efficiently. bitcrowd's first Elixir ML project dates back to 2020, and we have since then enabled various clients to build and scale their AI projects.
bitcrowd is an excellent choice if you need a scalable RAG system or a fully integrated AI pipeline. We help you build, optimize, and maintain it with a focus on reliability and performance.
Drop us a line via email if you want to build your next AI project with Elixir. Or book a call with us to discuss your project.
