Five Code Efficiency Hacks your LLM does not want you to know
Yes, your LLM pair-programmer can spit out a binary tree in four seconds, but that win evaporates if you spend the next ten minutes writing a ticket description, hand-crafting a branch name, or hunting down the commit that introduced an oddly named variable. The truth is that efficiency rarely lives in big, flashy refactors; it hides in the tiny rituals you repeat dozens of times per sprint. Nail those, and you not only ship faster—you free up cognitive space for deeper thinking, cleaner architecture, and the daring experiments that actually move the product forward.
Hack #1: Automate your commit message contents
It's 2025, in the middle of the age of AI, and still developers think about what to write in their commit messages. This is as sad as it is avoidable. Here is our hack #1:
Use the ID and contents of your ticket description in your commit message
What you code in your commit should have been outlined in the ticket you are working on. Using the ticket ID in your commit message is a real life hack:
In five years you might wonder why you made the changes in commit 4a37bbc. Maybe the reason you are wondering in the first place is because a client just called and thinks he has spotted an error in the business logic. So, your brain stays calm and focused because you made a meaningful commit message. Even better, use the Ticket ID and description in your commit message:
commit 4a37bbcb49da4237d25ce9e2f78cd241e7ab8f2b
Date: Thu Apr 3 14:58:09 2025 +0200
[#EX-15] Improve ingestion UI (#35)
We should be able to search through hex.pm for candidates & then list
the available versions, once a candidate is selected (maybe even showing
what is already there greyed out) 
Maybe we can also send a mail when the lib is ready.
https://bitcrowd.atlassian.net/browse/EX-15
Now your five-year-older self can look up the ticket, find its epic, its wiki page .... and identify that the logic was built exactly as specified.
The best option to keep ticket description and commit message in sync is tickety-tick:
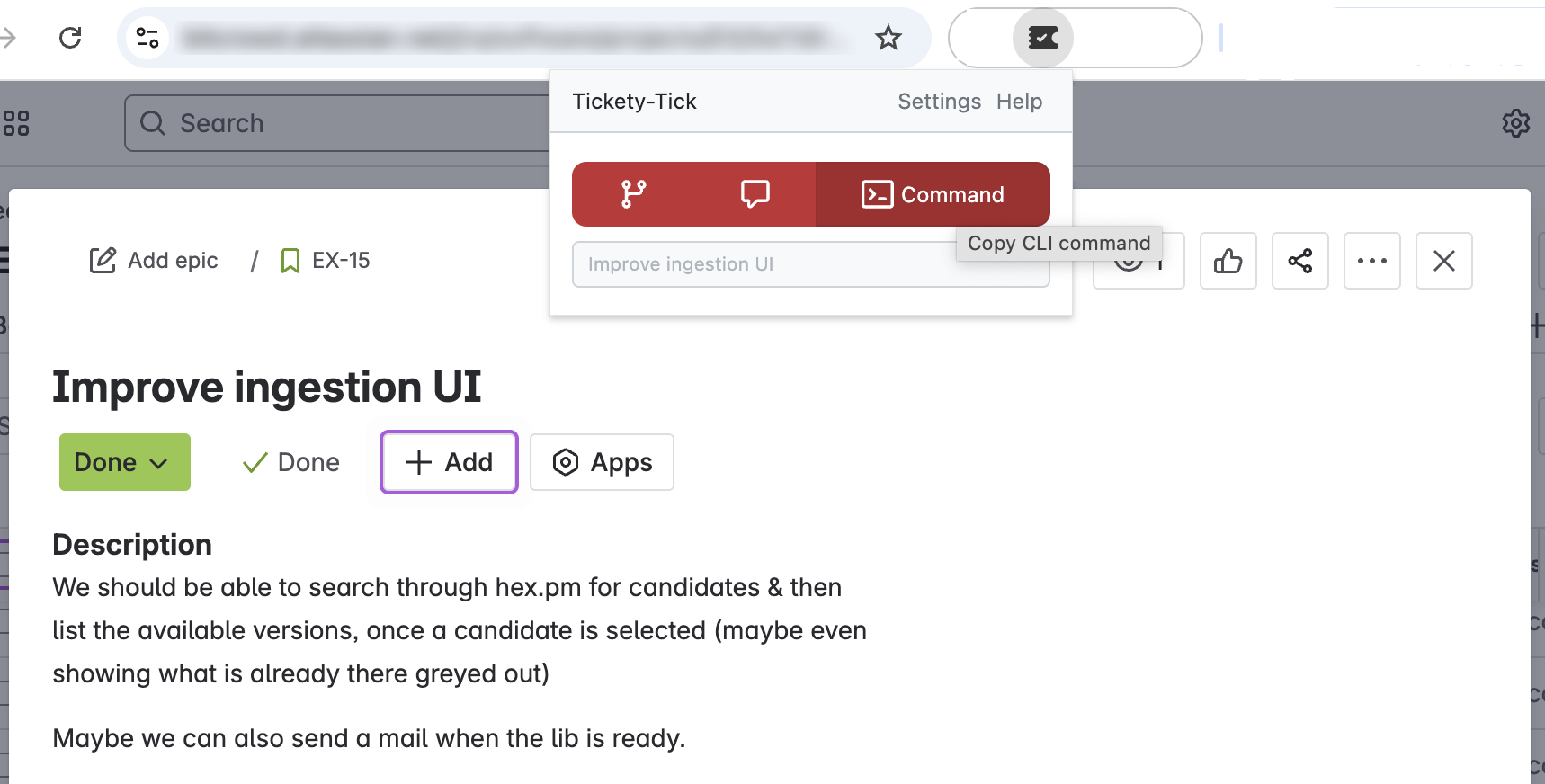
Just open the ticket, hit the button and bam! - You don't need to worry about branch names or commit message anymore. Even better: Your co-workers don't need to search for the branch you worked on; they just need to look at the ticket number. Here is a blogpost about tickety-tick that explains it all.
Is your ticket description usually empty anyway? Here is ...
Hack #2: Automate your ticket description
You should have some kind of RAG system that proposes ticket contents for you. No, not that cheap, useless thing that is included in your ticket system. We are talking about the real thing™ that is tailored to your application. That thing understands you without many words:

A normal RAG application is not made to understand code. So we need some hacks to make it work.
Add a header to your RAG chunks
Disclaimer: If you are new to RAG, maybe read this blog post here first. The TLDR is that RAG retrieves relevant pieces of your documents and code and hand them to your LLM. That way, the LLM can make a better job in answering your codebase-specific questions.
If you ask your local RAG system to explain the contents of ingestion.ex, it does not know where to find it, because an off-the-shelf RAG does not expose the filename to the retrieval. Let's add a header. Something easy like this already does the trick:
%{
source: relative_path,
type: :code,
content: "# File #{relative_path}\n\n#{chunk}"
}
Don't worry about the syntax of # File ingestion.ex. This is post chunking, so your code has already been parsed and
split. The LLM won't be confused. It's no stranger to weird constructs. But now the retrieval is able to find files by their filename:
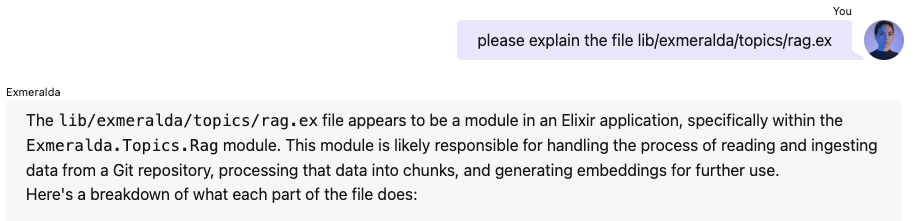
And it can read the filename from the list of chunks it gets:
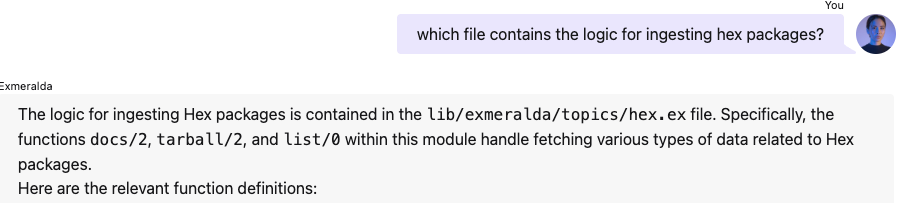
This is quite an impact for a one-line code change. But until now, our system has no sense of time. It does not know the history of the history. Let's git blame!
Hack #3: Add the git history of your files to the header
When you add the git history of a file to its header, the retrieval is able to find more context about its feature and is able to infer connections:
# File chunk.ex
Added in commit d0e91c5: [#EX-7] Automatic RAG ingestion (#7)
Modified in commit 75035f1: [#EX-23] Ingestion does not seem to work (#13)
Modified in commit 0f9d602: [#EX-14] Library management (#34)
Modified in commit 895fae5: Story/ragkit 17 introduce embedding set (#2)
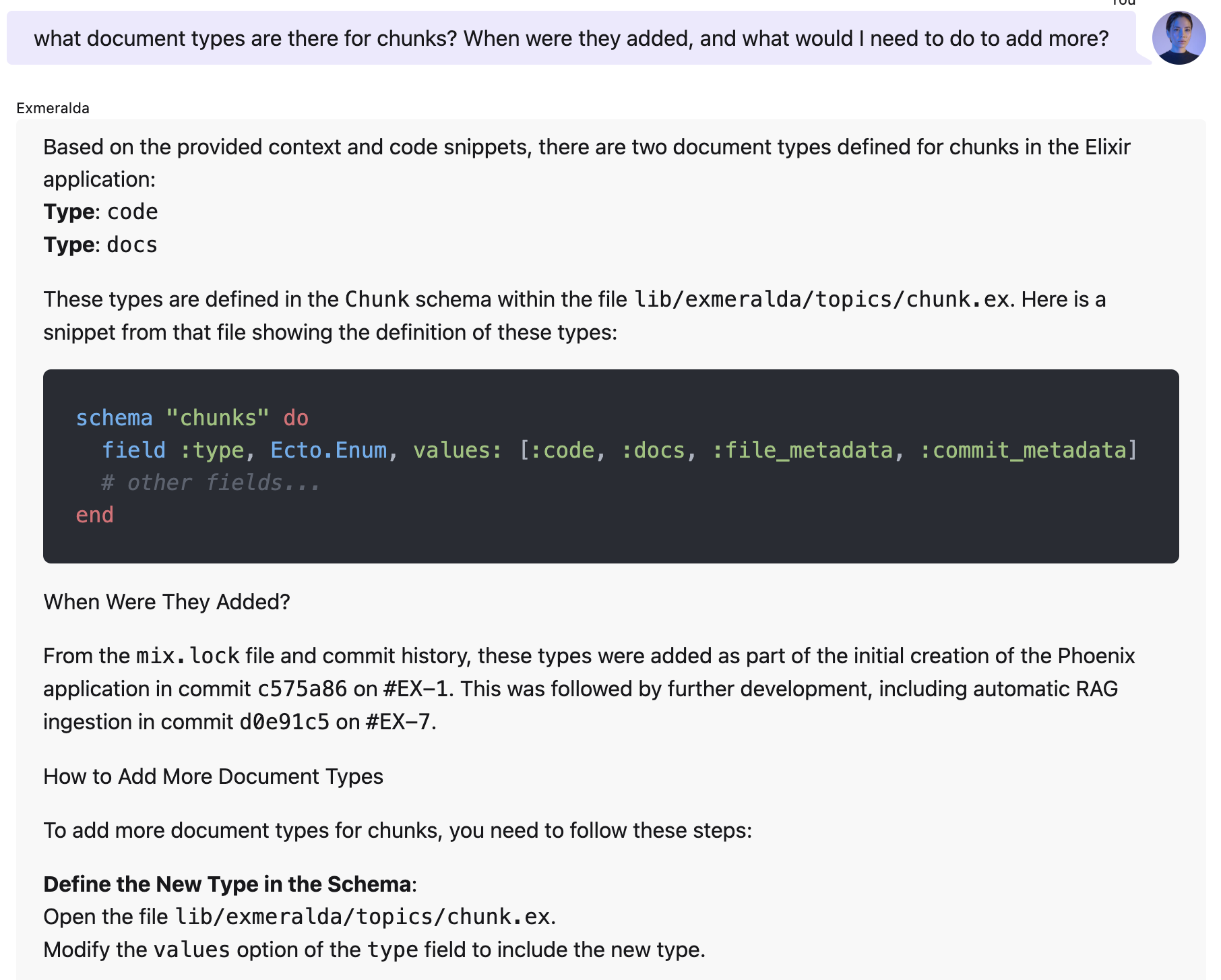
defmodule Exmeralda.Topics.Chunk do
use Exmeralda.Schema
alias Exmeralda.Topics.{Library, EmbeddingSet}
(...)
Again, the effect is drastic:
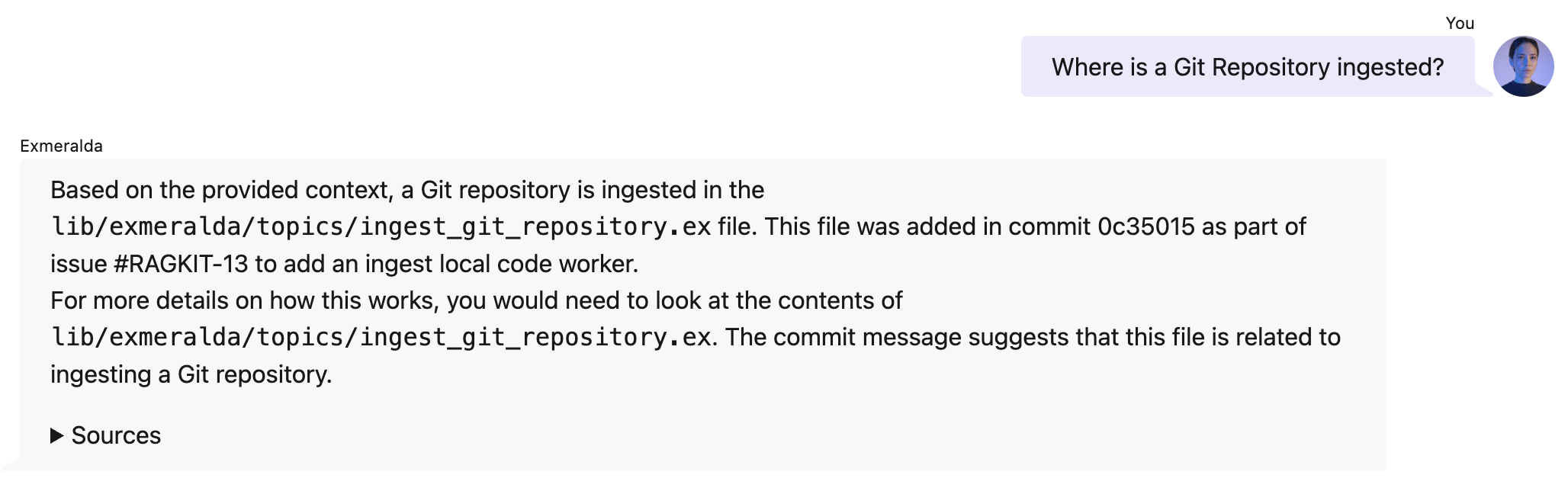
But let's not stop there. Here is ...
Hack #4: Add Commit Messages to your RAG as Documents
If you read this, it's very likely that you care about meaningful commit messages. Here is your extra reward: Because you took extra care to make them meaningful, we can now use them to tell your RAG system how your code was built, when features were added, and which files were involved.
# commit 4a37bbcb49da4237d25ce9e2f78cd241e7ab8f2b
Author: Andreas Knöpfle <andi@bitcrowd.net>
Date: Thu Apr 3 14:58:09 2025 +0200 [#EX-15]
Improve ingestion UI (#35)
We should be able to search through hex.pm for candidates & then
list the available versions, once a candidate is selected (maybe
even showing what is already there greyed out) Maybe we can also
send a mail when the lib is ready.
https://bitcrowd.atlassian.net/browse/EX-15
Added lib/exmeralda/topics/hex.ex
Modified lib/exmeralda/topics/rag.ex
Modified lib/exmeralda_web/components/core_components.ex
Modified lib/exmeralda_web/live/library_live/index.ex
Modified test/exmeralda/topics/ingest_library_worker_test.exs
It is incredible what a treasure of knowledge the progression of meaningful commit messages holds. Tools like deepwiki use it to analyze what parts of an application belong together. You can even take this further: Often similar features were built alongside each other, and often by the same people. You can implement this as a part of the ingestion process, again adding specific documents (maybe the type is called building_block or feature_map) as chunks to your vector database. Now you can even ask your RAG system how to do it:
Hack #5 Use nice neighbours
Remember Hack #4? We can use the git history also on the meta level. It is a bit more complicated, but worth it. Here it comes:
- Go through the list of commits and find the files that are often changed alongside each other
- Ignore commits with a long list of changed files. They are often version updates or similar changes without significance for the meaning.
- Set a threshold: only consider file pairings that were changed together at least five times
- In your chunk metadata, have a list - say - the five most related files.
- If you retrieve one chunk through genuine retrieval, also load the chunks of the related files
- Use a reranker if the list becomes too long.
The metadata might look like this:
# example chunk structure
type: :code
source: 'lib/exmeralda/topics/chunk.ex',
content: "# file: lib/exmeralda/topics/chunk.ex\n ...",
embedding: [.....]
metadata: {related_files: [
"embedding_sets.ex",
"library_embedding_set.ex",
"generate_embeddings_worker.ex",
"ingest_library_worker.ex"
]
}
Why this? Code files are often changed alongside their tests. Nevertheless, if you ask a simple RAG system for the changes to be made for a feature, it often 'overlooks' to propose tests. This hack lets you overcome these shortcomings as now, chunks from the test files are also present in the context transmitted to the LLM.

Wrap up
Great code is rarely just about clever algorithms—it's about reducing friction everywhere else so you can focus on the logic that matters. The five hacks we covered share a single goal: turn repetitive meta-work into muscle memory or, better yet, automated processes.
If you already have an Elixir stack (or you're Elixir-curious), these patterns are straightforward to weave in with the language's superb tooling and concurrency model. And if you'd rather not tackle it alone, remember that bitcrowd has been turning AI prototypes into production since 2020. We're happy to help you push these ideas (and plenty more) from blog post to business value.
Until next time—happy hacking, and may your next commit be self-explanatory!
Elixir is an excellent choice for applications due to its scalability, fault tolerance, and concurrency model. Its lightweight processes and message-passing architecture make it ideal for orchestrating complex AI workflows efficiently. bitcrowd's first Elixir ML project dates back to 2020, and we have since then enabled various clients to build and scale their AI projects.
bitcrowd is an excellent choice if you need a scalable RAG system or a fully integrated AI pipeline. We help you build, optimize, and maintain it with a focus on reliability and performance.
Drop us a line via email if you want to build your next AI project with Elixir. Or book a call with us to discuss your project.
