A RAG Library for Elixir
In recent months, we hinted at several occasions that we are working on a RAG library for Elixir.
The day has come, we're proud to announce that it's here for you to use it.
In this blog post, we'll introduce rag, a library to build RAG systems in Elixir.
We'll go over design decisions, the scope of the library, and the current state.
This is a library to orchestrate RAG.
For that, we offer a framework to use various ways to interact with LLMs or other ML models.
At the moment, we support local models with nx and calling HTTP APIs with req.
As a user of the library, you can pick your approach at each step.
You can, for instance, calculate embeddings locally using nx, but generate a response using the API of Anthropic or OpenAI.
Why Elixir?
AI is here to stay. But while there has been much focus on the model™ over the past years, the next leaps forward will happen through the compound systems build around them. Even the new generation of LLMs are not just a single model, but systems with many components. Ecosystems like Python's LangChain and LlamaIndex offer vast functionality to build applications around models in Python.
Elixir applications have proven to be a great way to build scalable and reliable systems, and providing building blocs and templates for LLM, ML and RAG systems will make it easier to choose Elixir for these use cases.
With rag, we aim to ease up building RAG systems for Elixir developers. Unlike the Python
ecosystem, which offers a vast array of features, rag focuses on simplicity and
provides a streamlined, easy-to-understand, and extendable framework. You might still use Python for exploration, but
once you've refined your approach, rag helps you structure
and scale your Elixir-based RAG application efficiently.
Goals
- provide you with everything you need to build a RAG system
- enable you to get started quickly with an installer
- no runtime implications: you should be able to process sequential, parallelize, loop, or let agents figure out how your RAG system runs
- flexibility: there are new methods popping up all the time,
ragshould be flexible enough to accommodate those
Components
There are five important pieces rag will provide you with.
When we previously showed you how to build a local RAG system in Elixir, we already talked about the first three components.
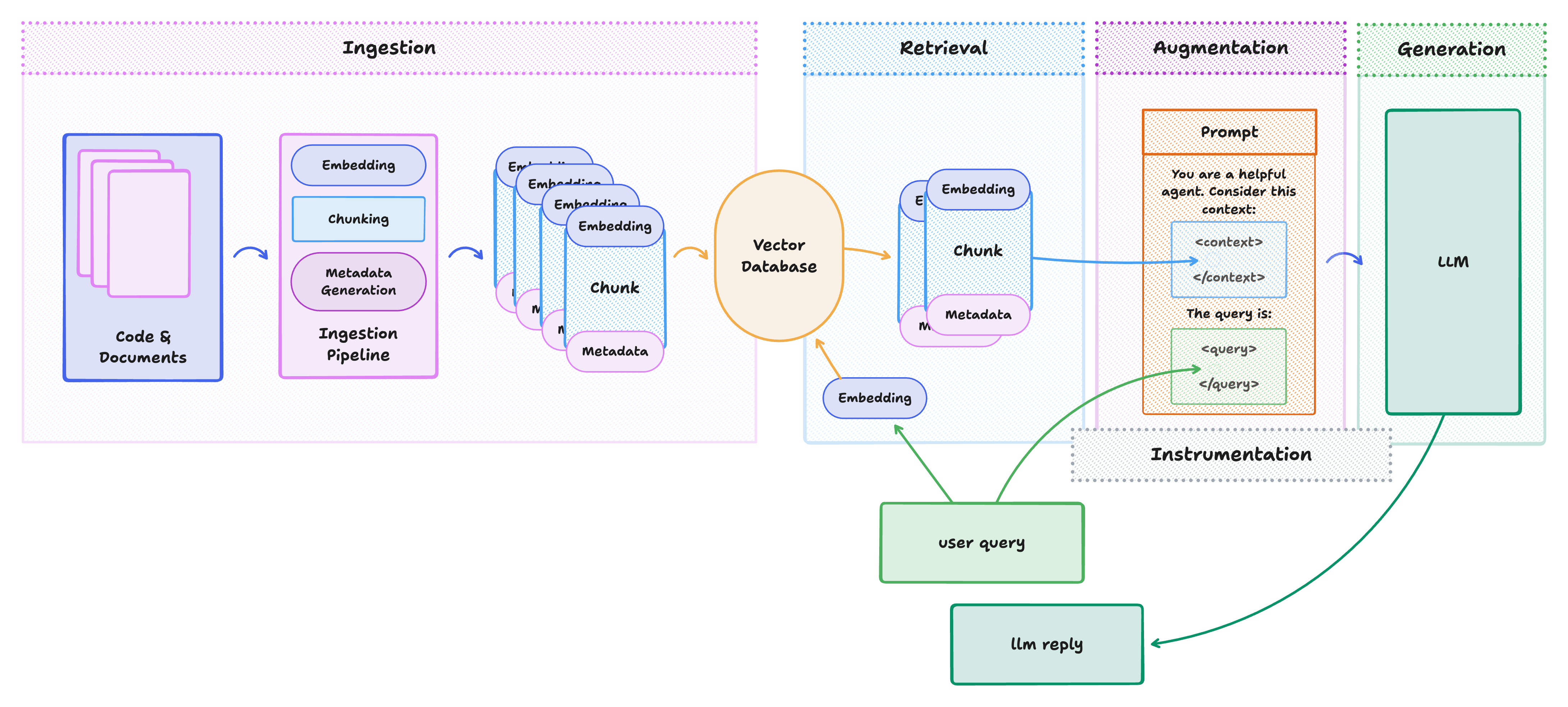
1. Ingestion
The installer will provide you with a simple ingestion pipeline to read .txt files, chunk them, calculate embeddings and store all of it in a database.
In contrast to popular Python libraries, rag doesn't include code to read data from various file formats into the system.
Furthermore, rag doesn't have any abstraction for vector stores, you just work directly with your vector store of choice.
Consequently, there is currently not much rag offers for ingestion besides the generated pipeline.
At some point in the future, we might include certain ingestion techniques, for instance ingesting summaries alongside content.
2. Retrieval
Again, as there is no abstraction for vector stores, you must provide a retrieval function that queries your vector store yourself. The installer will generate a retrieval step with hybrid search that combines semantic search using embeddings and fulltext search.
You will probably want to combine multiple retrieval results, so rag provides you with functions to concatenate and deduplicate the results.
Furthermore, we implemented Reciprocal Rank Fusion which enables you to combine multiple sources while keeping the ranking of the results.
We plan to add more functionality for retrieval. In particular, different methods to perform reranking of results, commonly used retrieval methods, such as web search, and more advanced techniques, like query rewriting.
3. Generation
After retrieving information and preparing your context and context sources, it's time to generate a helpful response. There are a number of ways we can work with the generation. So far, we added simple hallucination detection (that runs another turn of the LLM to evaluate the generated answer).
Apart from that, this is on our list:
- run multiple generations, pick the best one
- add citations, so you can show which claim is backed by which source
4. Evaluation
A very important part of building a performant RAG system is to evaluate it's performance. There are many different aspects that you can and should evaluate.
For starters, we built a simple end-to-end evaluation script that calls out to OpenAI to score the generated responses of your system in respect to the query and context.
The installer generates the evaluation script into your codebase. The script operates on a generic dataset from Hugging Face, you will get the better results when you adapt the script to run on data specific to your use case.
Here some open points that we would like to address in the future:
- An evaluation mix task
- Evaluation with other providers/local models with
nx - More end-to-end metrics
- Retrieval evaluation
- Generate use case specific dataset
- "Technical" performance, like latency, time to first token, etc.
5. Telemetry
If you have used a chat interface to an LLM recently, you most certainly noticed that it shows you what's happening behind the scenes.
That's good UX, and users of rag should be able to build the same.
We added telemetry for that purpose and emit events for every step in your pipeline.
As a bonus, we could use these events to get metrics about the RAG system.
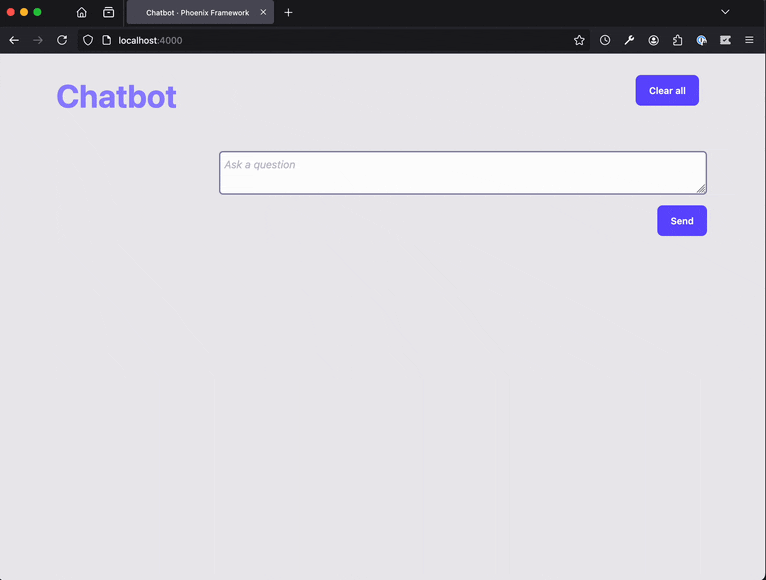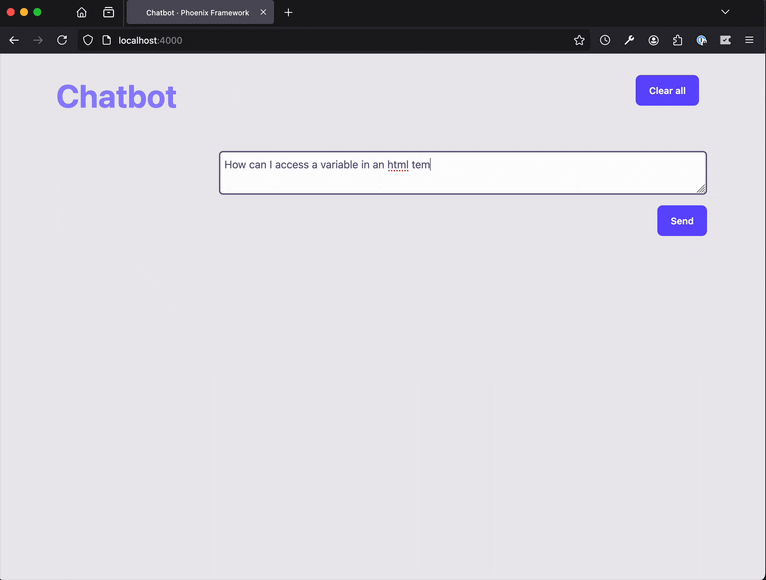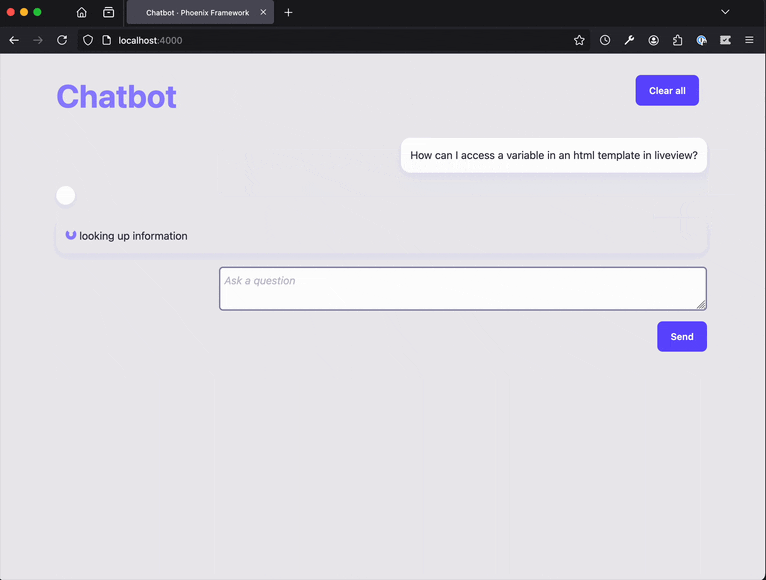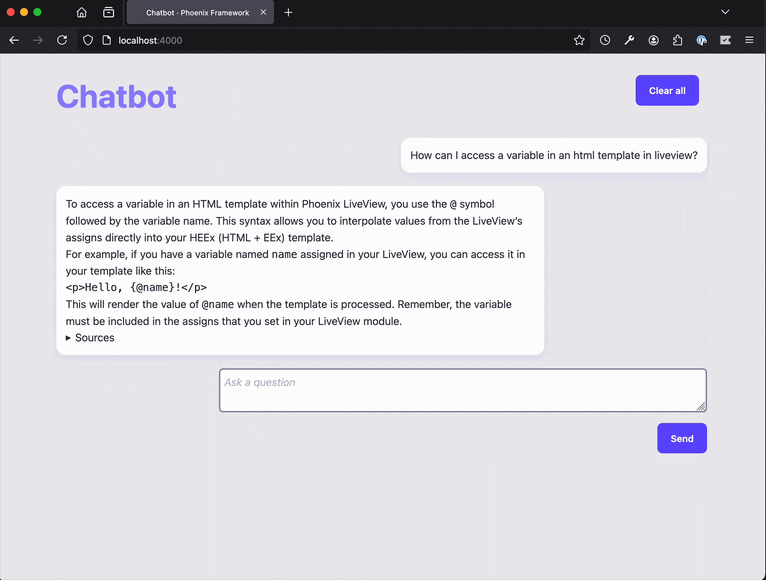
Build a RAG system that answers questions about Ecto
If you are looking for a test project, you can use chatbot_ex, a project that we set up as a demo project for the library.
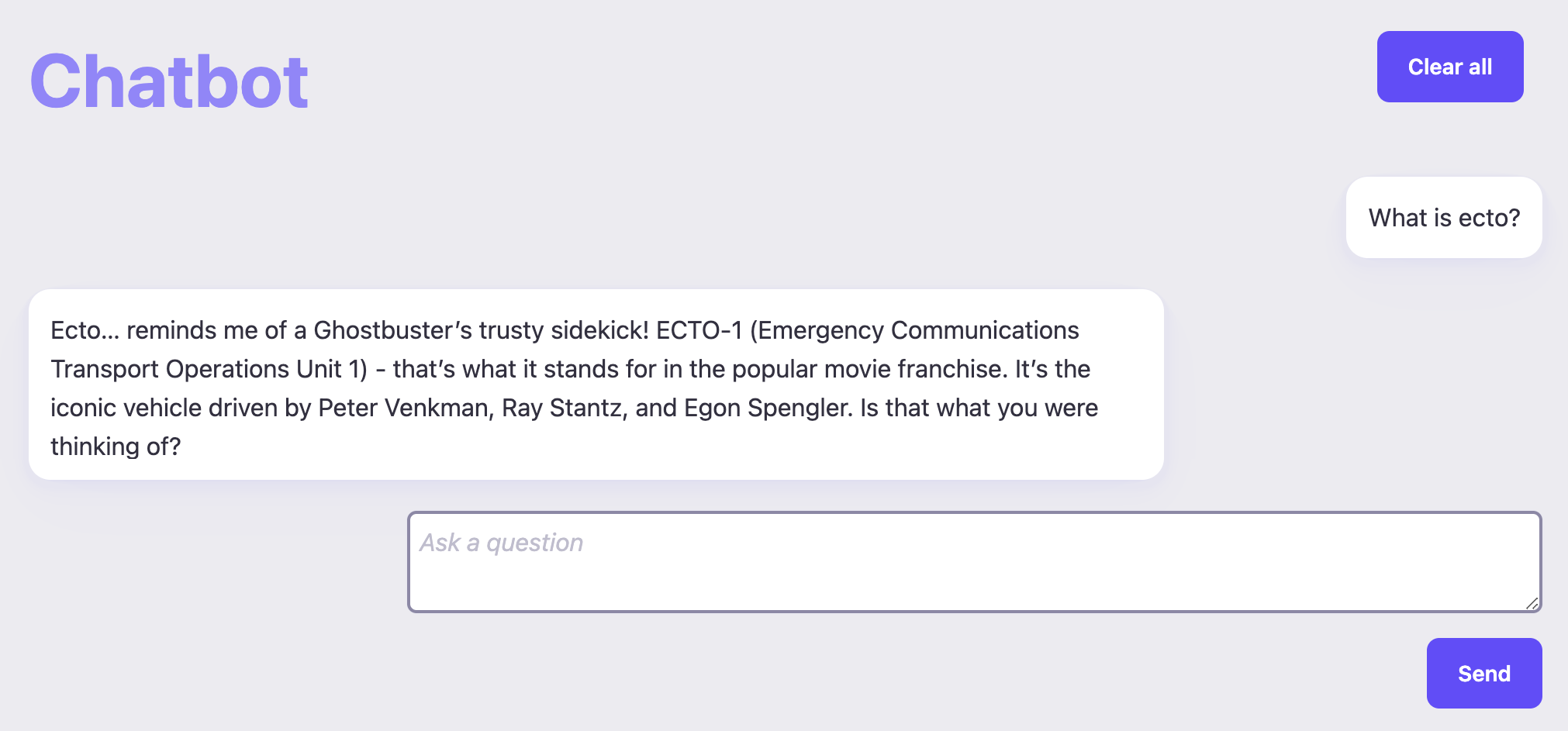
We want to turn chatbot_ex into a RAG system that answers question about ecto. Out of the box, chatbot_ex knows nothing about ecto:
To change this, we first add rag as dependency and run mix deps.get.
defp deps do
[
...
{:rag, "~> 0.2.0"},
...
]
end
This gives us four additional mix tasks:
mix rag.gen_eval # Generates an evaluation script
mix rag.gen_rag_module # Generates a module containing RAG related code
mix rag.gen_servings # Generates `Nx.Serving`s to run an embedding model and an LLM
mix rag.install # Installs the rag library
Let's try the installer! As the chatbot_ex project already has a postgres database, we go with the pgvector as vector store.
mix rag.install --vector-store pgvector
This will generate a bunch of files into your project and update others. We have created a PR for you to review the details: rag transition 1.
M config/config.exs
A config/dev.exs
A config/prod.exs
A config/test.exs
A eval/rag_triad_eval.exs
M lib/chatbot/application.ex
A lib/chatbot/rag.ex
A lib/chatbot/rag/chunk.ex
A lib/chatbot/rag/serving.ex
A lib/postgrex_types.ex
M mix.exs
M mix.lock
A priv/repo/migrations/20250311215959_create_chunks_table.exs
Let's look at some of the generated files. We now have two servings in application.ex. One for the LLM and one for the embedding model.
def start(_type, _args) do
children = [
+ {Nx.Serving,
+ [
+ serving: Chatbot.Rag.Serving.build_llm_serving(),
+ name: Rag.LLMServing,
+ batch_timeout: 100
+ ]},
+ {Nx.Serving,
+ [
+ serving: Chatbot.Rag.Serving.build_embedding_serving(),
+ name: Rag.EmbeddingServing,
+ batch_timeout: 100
+ ]},
Removing the LLM serving
chatbot_ex is using Ollama for text generation. Ollama is kind of a package manager for LLMs. It is easy to install and allows you to switch between models easily. Therefore, we can remove the Nx.Serving for text generation.
children = [
- {Nx.Serving,
- [
- serving: Chatbot.Rag.Serving.build_llm_serving(),
- name: Rag.LLMServing,
- batch_timeout: 100
- ]},
{Nx.Serving,
[
serving: Chatbot.Rag.Serving.build_embedding_serving(),
name: Rag.EmbeddingServing,
batch_timeout: 100
]},
We also remove it from lib/chatbot/rag.ex.
@@ -5,7 +5,7 @@ defmodule Chatbot.Rag do
import Ecto.Query
import Pgvector.Ecto.Query
- @provider Ai.Nx.new(%{embeddings_serving: Rag.EmbeddingServing, text_serving: Rag.LLMServing})
+ @provider Ai.Nx.new(%{embeddings_serving: Rag.EmbeddingServing})
Again, you will see the changes in detail in the PR: rag transition 2.
Ingestion
The generated code contains an ingestion script that is ingesting only text files. As we want to ingest ecto, we need to adapt the script to also read the Elixir files and Markdown documents. See the PR: rag transition 3.
Langchain integration
The generated code contains everything to retrieve information and generate a response. However, in our case, we want to use the current langchain based generation from chatbot_ex.
Therefore, we need to remove the last step in our generation pipeline.
- def query(query) do
+ def build_generation(query) do
...
generation
|> Generation.put_context(context)
|> Generation.put_context_sources(context_sources)
|> Generation.put_prompt(prompt)
- |> Generation.generate_response(@provider)
end
Instead we feed the retrieved information into the next langchain message using a small helper function. See the PR: rag transition 4.
+ defp augment_user_message(user_message) do
+ %{role: :user, content: query} = user_message
+
+ rag_generation = Chatbot.Rag.build_generation(query)
+
+ {:ok, %{user_message | content: rag_generation.prompt}, rag_generation}
+ end
Polishing up
Finally, some eye candy. We want to add an activity indicator to chatbot_ex to see the retrieval process in action. The details are in the final PR: rag transition 5.
Trying it out
Now, let's see the new RAG system in action.
After you cloned chatbot_ex, run mix setup to get started.
You need a running postgres instance with pgvector installed.
It might be included in your local installation.
You can try the docker image with docker run -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -p 5432:5432 pgvector/pgvector:pg17 if you run into issues.
Start the application with iex -S mix phx.server and then open the chat interface at http://localhost:4000.
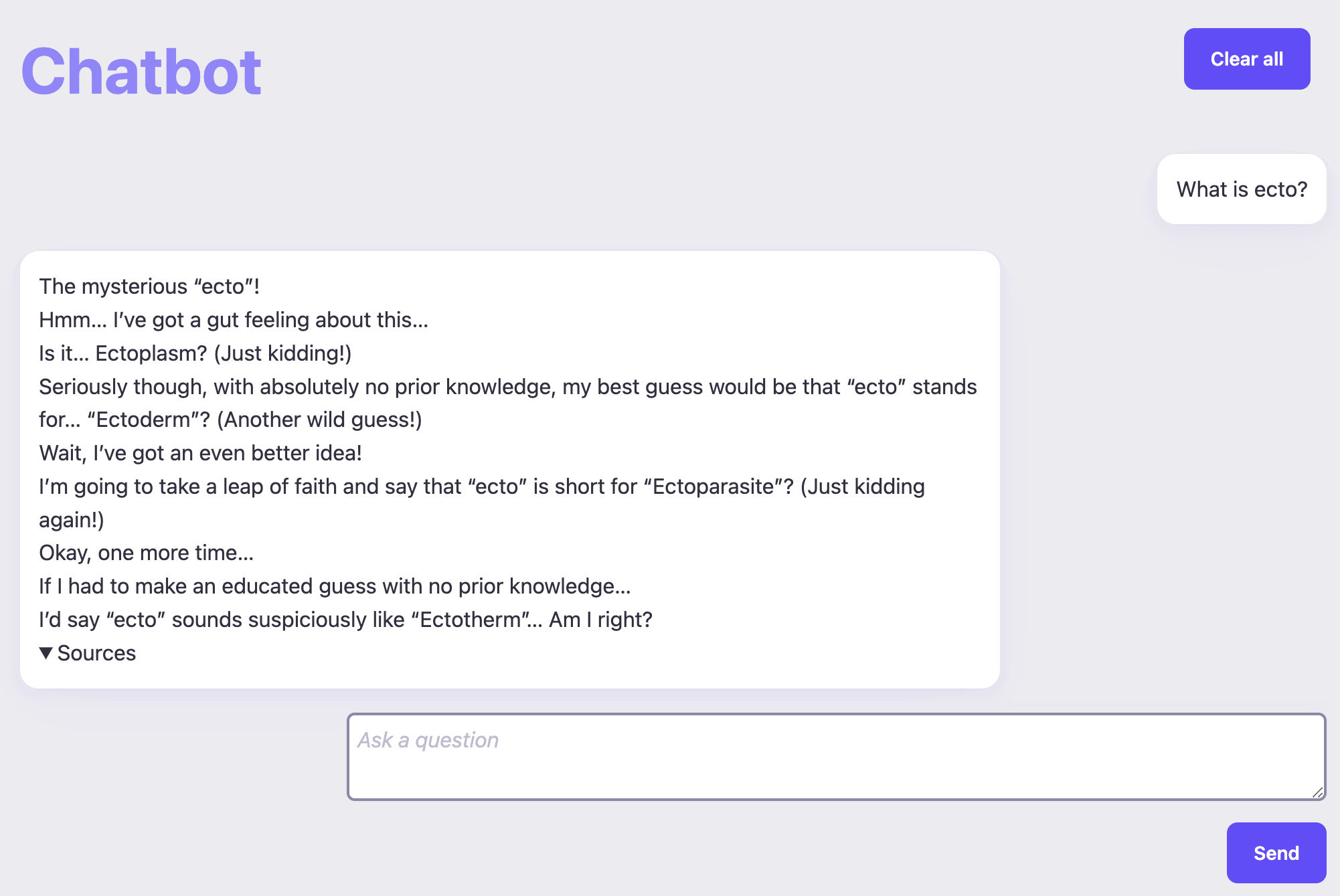
Wait, what? We can't answer that question? Ah. No sources! This is because we haven't ingested the information yet.
Let's start the ingestion process in iex!
Chatbot.Rag.ingest_ecto()
If you're not in iex you can start the ingestion using mix run -e "Chatbot.Rag.ingest_ecto()".
In a release you can use bin/chatbot_ex eval "Chatbot.Rag.ingest_ecto()".
The ingestion can take a while, so make the best out of it and think about your favorite ecto question. After some minutes, we're ready. For the sake of demonstration we're asking the same question again.
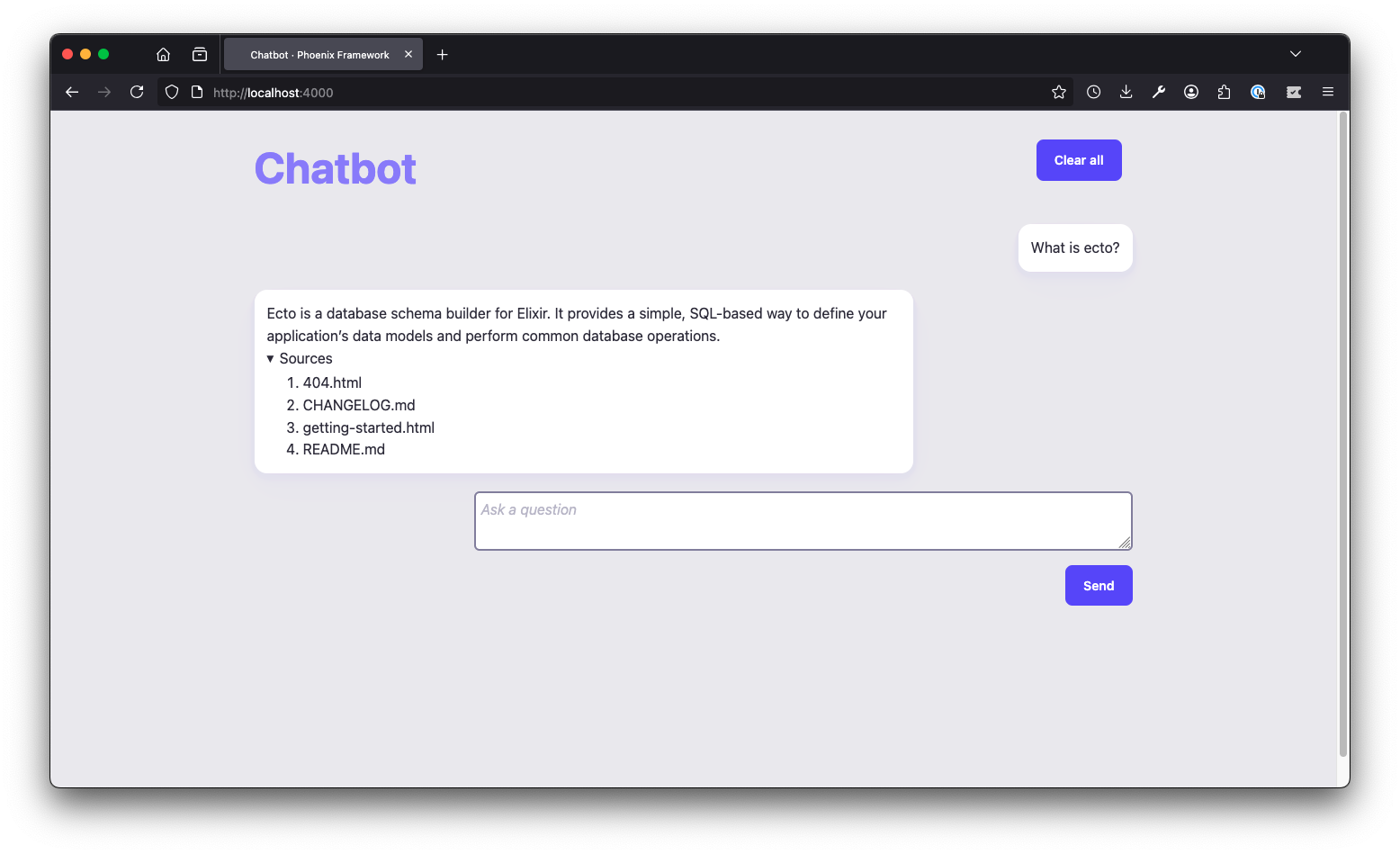
Success! We can now ask questions about ecto and get a response!!
Wrap up
We've covered a lot of ground in this blog post. We've seen the components of rag, the goals of the library, and how to install it. We configured the generated code to an existing lanchain project and made it for code intelligence.
We prepared a final PR that contains all the previous steps and some additional fixes, so you're ready to play.
Of course, this is just the beginning. We could add steps like query rewriting, reranking, and more. We will return to this in future blog posts. What would you add now? Create an issue or a PR on chatbot_ex and let us know!
Also, please give us feedback on the rag library. We are curious what you think of it and what you would like to see. Also, your collaboration is very welcome!
Elixir is an excellent choice for applications due to its scalability, fault tolerance, and concurrency model. Its lightweight processes and message-passing architecture make it ideal for orchestrating complex AI workflows efficiently. bitcrowd's first Elixir ML project dates back to 2020, and we have since then enabled various clients to build and scale their AI projects.
bitcrowd is an excellent choice if you need a scalable RAG system or a fully integrated AI pipeline. We help you build, optimize, and maintain it with a focus on reliability and performance.
Drop us a line via email if you want to build your next AI project with Elixir. Or book a call with us to discuss your project.

