TL;DR
Add an upload key to your configuration in config/storage.yml to set the Cache-Control header for uploaded files:
amazon:
service: S3
upload:
cache_control: "max-age=86400, private"
Caching?
I just had a memorable TIL moment with Ruby on Rails' Active Storage and caching.
It happened while working on a React app with a small Rails API backend. The app was displaying loads of images of various types, dimensions and file sizes and one would expect the browser to cache them after their initial retrieval from the backend. Caching these images on the client means sending less data over the wire on subsequent interactions and a smoother user experience when re-rendering components or re-loading the page. Unfortunately, in our case browsers were not caching any images which resulted in noticeable performance impacts and a flickering UI for users. With this caching issue, the app was wasting resources and sucking up its users' network traffic 🚨.
Inspecting image requests and responses in the "network" tab of the browser's devtools, we see images being retrieved freshly with a 200 OK status and this Cache-Control response header:
max-age=0, must-revalidate
The max-age=<seconds> directive specifies the amount of time the browser can treat a resource as "fresh" after its last retrieval. Within that period it may serve a cached copy before actually checking back with the server again. In our case this is set to zero seconds, so images are instantly considered "stale". The must-revalidate directive instructs the browser to never serve a stale, cached version of the resource but first "validate" whether the resource is up to date by asking the server again.
With this response header, the browser is essentially instructed to not cache images. Why are we doing this?
Detective Game
In our setup, image are uploaded and served by the backend API. It uses Active Storage under the hood, a framework offered by Rails for uploading files to various cloud services like Amazon S3 or Microsoft Azure and attaching them to Active Record models. Active Storage adds an extra layer of abstraction between the file upload in the app and its actual storage location on a remote cloud service: Rails only stores the upload's metadata and a reference to identify it on the storage service. It does not store actual file content. Requests for file uploads go through the Rails server first, which then returns the URL of the actual file location on the cloud service. So in our app, retrieving an image actually consists of two requests:
- Request the file from the backend API
- Request the original file from Amazon S3 (the cloud service we use)
The response for the first request is a redirect containing the actual file URL for the second request in its Location response header.
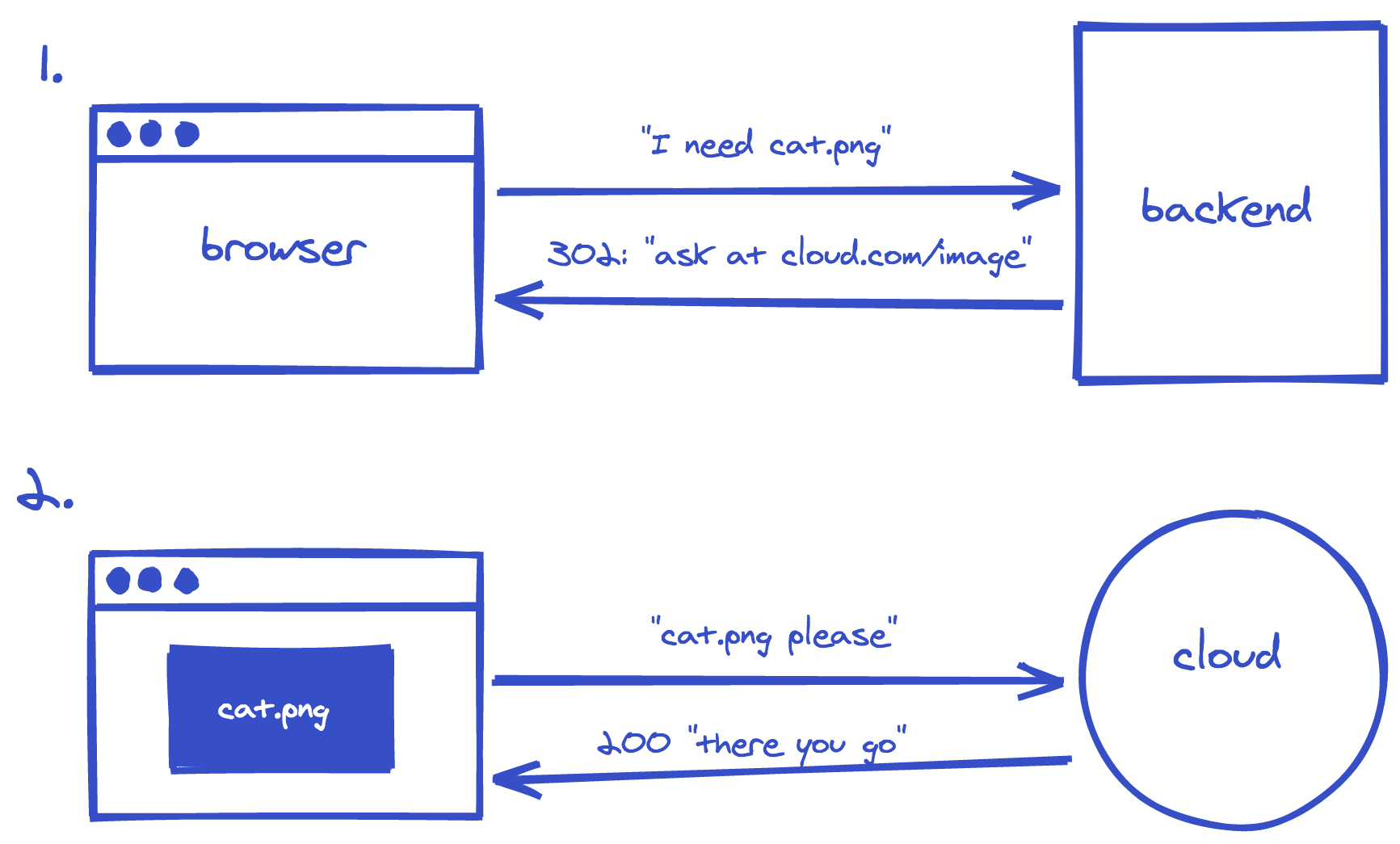
Looking at the network tab, we see the 302 Found redirect response for the first request already being cached correctly. The devtools state a "(from disk cache)" info and the Cache Control header matches as well:
max-age=10800, private
It instructs the browser to treat the resource as "fresh" for 10800 seconds (three hours) and "private", which means it's intended for a single user and may not be stored in a cache shared among multiple users. Rails allows to configure the expiry time of these redirect URLs generated by Active Storage. It defaults to five minutes, but our API already had it set to:
ActiveStorage::Service.url_expires_in = 3.hours
This is what we want: spare extra network requests by storing responses to frequently requested resources on disk. But why do we only cache the redirect responses, not the resource-heavier one for the actual image on S3?
Dead End
With caching enabled in development, I started an investigation around our setup and configuration for Active Storage and direct uploads. After hitting walls for hours and still being stuck with no-cache or max-age=0, private, must-revalidate Cache Control response headers for image requests, I realized: I am looking at the wrong thing! Besides integrating with cloud providers, Active Storage also has a local disk-based storage backend which we use in development. Intended for the test and development environment, this backend does not even support caching. And even worse: I was looking at image responses from our Rails server for hours, while in production the requests target Amazon S3. It's Amazon who puts together the response headers, not our servers 🙈.
So I set up a bucket on S3 and changed my setup to target Amazon for file uploads. Now image requests were served by Amazon S3 (success!). Still the Cache Control header was wrong and nothing cached…
Looking at the S3 docs and blindly clicking around, I found out I can set the respective Cache Control header editing the "metadata" of my uploads directly on S3 🎉
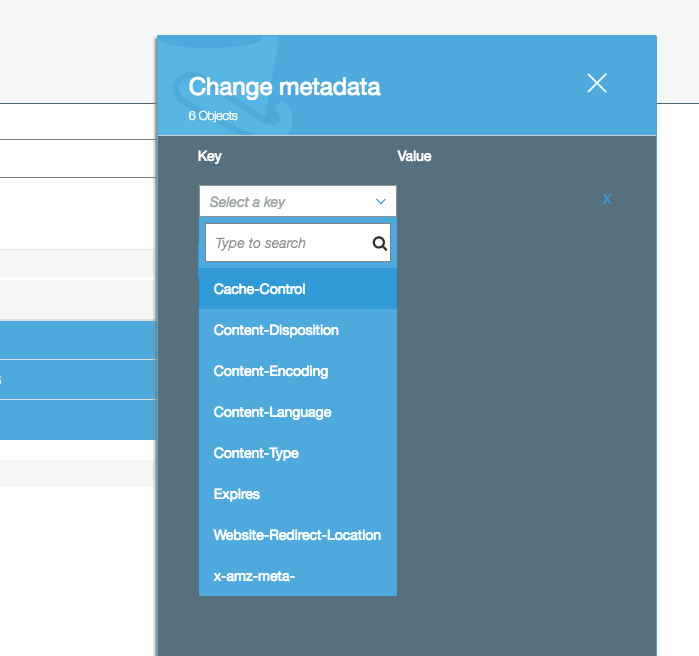
With our app not offering any means for updating existing images, I set the value to:
max-age=86400, private
It instructs the browser to consider the resource "fresh" for 24 hours and store it only for the single user.
And - 🍾 - it worked! The response from S3 had the right header and the browser started caching images! The network tab indicated a 200 OK (from disk cache) as status code now.
So all done, problem solved 👋.
But… new uploads of course didn't have the header and weren't cached. Editing metadata on S3 also felt too weird to be an actual solution. The information should be provided by Active Storage instead. A wise person on Stackoverflow then pointed me to this line in the Active Storage source code:
def initialize(bucket:, upload: {}, public: false, **options)
@client = Aws::S3::Resource.new(**options)
@bucket = @client.bucket(bucket)
@multipart_upload_threshold = upload.fetch(:multipart_threshold, 100.megabytes)
@public = public
@upload_options = upload
@upload_options[:acl] = "public-read" if public?
end
Initializing the S3Service allows to pass an optional upload hash. The service uses the aws-sdk-s3 gem under the hood and passes the contents of this upload hash as additional arguments to the put or upload_stream methods called on the underlying Aws::S3::Object when uploading files 💡.
def upload_with_single_part(key, io, checksum: nil, content_type: nil, content_disposition: nil)
object_for(key).put(body: io, content_md5: checksum, content_type: content_type, content_disposition: content_disposition, **upload_options)
rescue Aws::S3::Errors::BadDigest
raise ActiveStorage::IntegrityError
end
With this knowledge, I checked the docs for put's arguments and found:
:cache_control (String) — Can be used to specify caching behavior along the request/reply chain
Jackpot 🎰!
So we put something like this into config/storage.yml:
amazon:
service: S3
access_key_id: <%= ENV.fetch('AWS_ACCESS_KEY') %>
secret_access_key: <%= ENV.fetch('AWS_SECRET_KEY') %>
region: eu-central-1
bucket: <%= ENV.fetch('S3_BUCKET') %>
upload:
cache_control: "max-age=86400, private"
Now the Cache Control metadata is set when uploading (also for direct uploads) and files are served with the right response headers, allowing the browser to happily do its caching work 🤗
