Abstract
This is the first part of a series of blog posts on using a RAG (Retrieval Augmented Generation) information system for coding. Find out how this can empower your development team.
In this episode, we will discuss at a very simple RAG system for Ruby made with LangChain, JinaAI embeddings and a very light local LLM served via Ollama.
If you donʼt know what any of this means, this blog post is for you. You will see how to benefit from the technology without uploading/donating your codebase to external providers like OpenAI.
It is an introduction, the coding follows in the next episodes.
Naming is hard, and I wanted something that goes against the flashy-ai-y. So letʼs call this a Granny RAG.
The next parts will then move on to the following topics:
- examine different embedding models
- splitting and chunking strategies
- RAG for and with Elixir
Letʼs start.
A Use Case
Imagine you are developer and you just started a new job. The code base looks well maintained, the team is nice. Could be bitcrowd. You grab your first ticket, and it looks like this:
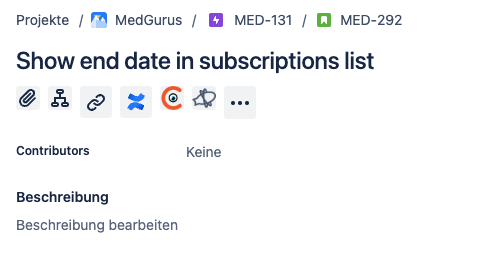
Uff. No description. Normally, you would reach out to your onboarding-buddy and ask for advise. This ticket is clearly written with a developer who knows the application in mind.
But ... you could also quickly investigate. Your team does have a Granny after all!
You go to your local granny. Granny RAG is in fact just some light off-the-shelf application wrapper around a simple RAG system, but you are used to call her Granny RAG, because she is patient, kind and knows all the stories.
Letʼs ask her:
Hy Granny, I need to show the end date of the subscriptions in the “subscription list”. What is a subscription in the application?
Granny: To display the end dates of subscriptions in the list of subscriptions, you can modify the COLLECTION_ATTRIBUTES constant in your SubscriptionDashboard class to include the active_until field. Hereʼs an updated version of the SubscriptionDashboard class with the modified COLLECTION_ATTRIBUTES:
class SubscriptionDashboard < ApplicationDashboard
ATTRIBUTE_TYPES = {
course: Field::BelongsTo.with_options(order: :name),
user: Field::BelongsTo.with_options(order: :name),
user_id: Field::Number,
id: Field::String,
active_until: Field::DateTime,
deactivated_at: Field::DateTime,
active?: Field::Boolean,
product_type: EnumField,
created_at: Field::DateTime,
updated_at: Field::DateTime
}.freeze
COLLECTION_ATTRIBUTES = %i[
course
user
id
active?
product_type
active_until
].freeze
Wow, this is magic!
Without knowing the application too well, you came from a non-workable ticket to a plan of action. You can now chose to update the ticket description, or create a PR and use that for the discussion.
This is a real life ticket from a client.
This ticket came from the work at our client MedGurus. When I tried out my Granny RAG, I browsed through the tickets in progress and found this one. I compared the solution Granny RAG proposed with the PR that came out of this ticket. I was actually thrilled how well this works.
My conversation with Granny RAG was actually a a bit longer:
Here is the full conversation with Granny RAG:
1. Question
Me: Hy Granny, I need to show the end date of the subscriptions in the “subscription list”. what is a subscription in this application?
Granny RAG: The subscription list in the application shows the end date of the subscriptions for each course that a user has access to. A subscription is a relationship between a user and a course, which indicates that the user has purchased or been given access to the courseʼs content. The list includes information about the type of product (e-learning or compendium) and the number of days remaining until the subscription expires.
The context provided contains code related to the SubscriptionDashboard class, which is used to display a list of subscriptions for a user on the dashboard page. The class defines attributes and methods to help with the display of this information, such as ATTRIBUTE_TYPES, COLLECTION_ATTRIBUTES, SHOW_PAGE_ATTRIBUTES, and FORM_ATTRIBUTES.
The DeactivateOldSubscriptions class is also defined in the context, which has a method called call that updates all subscriptions where the deactivated at field is nil and the active until field is less than the current time. This is used to automatically deactivate old subscriptions when they expire. The context also includes migration files for creating the Subscriptions table, as well as a TrailSubscriptionGatekeeper class that helps determine whether a user can access a particular course or not based on their subscription status and other factors.
Sources:
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb',
'source': 'medgurus-learningplatform/app/services/deactivate_old_subscriptions.rb',
'source': 'medgurus-learningplatform/db/migrate/20171107145726_create_subscriptions.rb'},
'source': 'medgurus-learningplatform/app/services/trail_subscription_gatekeeper.rb',
'source': 'medgurus-learningplatform/spec/features/user_profile_spec.rb'
2. Follow-Up
Me: Thank you, Granny. what would I need to do to display the end date of a subscription in the list of subscriptions inside the SubscriptionDashboard?
Granny RAG: To display the end date of a subscription in the list of subscriptions in the SubscriptionDashboard, you can use the active_until attribute of the Subscription model.
Hereʼs an example of how to do this:
class SubscriptionDashboard < ApplicationDashboard
ATTRIBUTE_TYPES = {
course: Field::BelongsTo.with_options(order: :name),
user: Field::BelongsTo.with_options(order: :name),
user_id: Field::Number,
id: Field::String,
active_until: Field::DateTime,
deactivated_at: Field::DateTime,
active?: Field::Boolean,
product_type: EnumField,
created_at: Field::DateTime,
updated_at: Field::DateTime
}.freeze
COLLECTION_ATTRIBUTES = %i[
course
user
id
active?
product_type
].freeze
SHOW_PAGE_ATTRIBUTES = %i[
id
user
course
product_type
created_at
active_until
deactivated_at
updated_at
].freeze
FORM_ATTRIBUTES = %i[
active_until
deactivated_at
active?
product_type
].freeze
endIn this example, weʼve added the active_until attribute to the SHOW_PAGE_ATTRIBUTES list, which will display the end date of each subscription on the show page. Weʼve also removed the deactivated_at attribute from the COLLECTION_ATTRIBUTES list, as we donʼt want to display it in the collection of subscriptions.
To display the end date of a subscription in the collection of subscriptions, you can use the active_until attribute of the Subscription model in your view code like this:
<% @subscriptions.each do |subscription| %>
<%= subscription.course.name %>
<%= subscription.user.email %>
<%= subscription.active_until %>
<% end %>This will display the name of the course, the email address of the user, and the end date of each subscription in the collection.
Sources:
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb'
'source': 'medgurus-learningplatform/app/services/deactivate_old_subscriptions.rb'
'source': 'medgurus-learningplatform/db/migrate/20171107145726_create_subscriptions.rb'
'source': 'medgurus-learningplatform/app/services/trail_subscription_gatekeeper.rb'
'source': 'medgurus-learningplatform/spec/features/user_profile_spec.rb'
3. Follow-Up
Me: Thank you! Please explain the functionality, workings, and structure of the SubscriptionDashboard to me
Granny RAG: The SubscriptionDashboard is a Ruby on Rails application that allows administrators to manage and edit subscriptions. It uses the administrate gem to provide an interface for creating, editing, and deleting subscriptions. The dashboard also provides information about active subscriptions, including the number of active users and the total amount spent on active subscriptions.
The SubscriptionDashboard is implemented as a subclass of the ApplicationDashboard class provided by the administrate gem. This allows it to inherit the functionality and structure of the parent class, which provides a standard set of features for managing data in an administrative interface.
The SubscriptionDashboard specifies the attributes that are displayed on the subscription dashboard through the ATTRIBUTE_TYPES constant. This includes fields for the course, user, ID, active status, product type, and creation and update timestamps. The COLLECTION_ATTRIBUTES, SHOW_PAGE_ATTRIBUTES, and FORM_ATTRIBUTES constants are also used to specify the attributes that are displayed on different pages of the dashboard.
The SubscriptionDashboard provides a standard set of features for managing data in an administrative interface, including the ability to create, edit, and delete subscriptions. It also provides information about active subscriptions, including the number of active users and the total amount spent on active subscriptions.
Sources:
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb'
'source': 'medgurus-learningplatform/app/models/subscription.rb'}
'source': 'medgurus-learningplatform/spec/features/admin/subscription/edit_spec.rb'
'source': 'medgurus-learningplatform/app/controllers/admin/pending_subscriptions_controller.rb'
'source': 'medgurus-learningplatform/spec/features/medical_test_dashboard_spec.rb.'
4. Follow-Up
Me: Thank you for explaining! Do the COLLECTION_ATTRIBUTES specify what is shown in the list of subscriptions?
Granny RAG: Yes, the COLLECTION_ATTRIBUTES specify what is shown in the list of subscriptions. The COLLECTION_ATTRIBUTES define which attributes are displayed for each subscription in the table on the subscriptions page. In this case, the COLLECTION_ATTRIBUTES include the course name (course), user name (user), ID (id), and product type (product_type).
The SHOW_PAGE_ATTRIBUTES define which attributes are displayed on the show page for each subscription. In this case, the SHOW_PAGE_ATTRIBUTES include the course name (course), user name (user), ID (id), product type (product_type), created at time (created_at), active until time (active_until), deactivated at time (deactivated_at), and updated at time (updated_at).
The FORM_ATTRIBUTES define which attributes are editable on the edit page for each subscription. In this case, the FORM_ATTRIBUTES include the active until date (active_until) and deactivated at date (deactivated_at).
Sources:
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb'
'source': 'medgurus-learningplatform/db/migrate/20191202204701_add_book_content_for_sub_test_array_to_subscriptions.rb'
'source': 'medgurus-learningplatform/spec/features/user_profile_spec.rb'
'source': 'medgurus-learningplatform/app/models/user.rb'
'source': 'medgurus-learningplatform/db/migrate/20221021100112_fix_active_until_calculation_on_subscriptions.rb'
5. Follow-Up
Me: What would I need to change to show the active_until date in the list of subscriptions?
Granny RAG: To show the active_until date in the list of subscriptions, you can add a new column to the subscriptions table with the type of date. Then, you can update the subscriptions table with the correct value for each subscription. Hereʼs an example of how you could do this:
class AddActiveUntilToSubscriptions < ActiveRecord::Migration[6.1]
def change
add_column :subscriptions, :active_until, :date
Subscription.all.each do |subscription|
subscription.update(active_until: subscription.deactivated_at || (subscription.product_type == 'e_learning' ? (DateTime.now + > active_months('e_learning').months) : (DateTime.now + active_months('compendium').months)))
end
end
end
This will add a new column called active_until to the subscriptions table, and then update each subscription with the correct value for its active_until date based on its deactivated_at field and product_type. The active_months method is defined in the previous migration as:
def active_months(product_type)
Rails.application.config.subscription_migration_active_months.fetch(product_type)
endThis will retrieve the correct number of months to add to the current date for each subscription based on its product_type.
Sources:
'source': 'medgurus-learningplatform/db/migrate/20221021100112_fix_active_until_calculation_on_subscriptions.rb'
'source': 'medgurus-learningplatform/spec/services/deactivate_old_subscriptions_spec.rb'
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb'
'source': 'medgurus-learningplatform/app/controllers/admin/pending_subscriptions_controller.rb'
'source': 'medgurus-learningplatform/spec/features/medical_test_dashboard_spec.rb
6. Follow-Up
Me: You said before that the
COLLECTION_ATTRIBUTESare responsible for the list ofSubscriptionsin theSubscriptionDashboard. Your further said thatactive_untilis the field of the subscription model that holds the information about the end date of the subscription. How would I need to change the SubscriptionDashboard, so that the the end dates of subscriptions are displayed in the list of subscriptions?
Granny RAG: To display the end dates of subscriptions in the list of subscriptions, you can modify the COLLECTION_ATTRIBUTES constant in your SubscriptionDashboard class to include the active_until field. Hereʼs an updated version of the SubscriptionDashboard class with the modified COLLECTION_ATTRIBUTES:
class SubscriptionDashboard < ApplicationDashboard
ATTRIBUTE_TYPES = {
course: Field::BelongsTo.with_options(order: :name),
user: Field::BelongsTo.with_options(order: :name),
user_id: Field::Number,
id: Field::String,
active_until: Field::DateTime,
deactivated_at: Field::DateTime,
active?: Field::Boolean,
product_type: EnumField,
created_at: Field::DateTime,
updated_at: Field::DateTime
}.freeze
COLLECTION_ATTRIBUTES = %i[
course
user
id
active?
product_type
active_until
].freeze
SHOW_PAGE_ATTRIBUTES = %i[
id
user
course
product_type
created_at
updated_at
].freeze
FORM_ATTRIBUTES = %i[
active_until
deactivated_at
].freeze
endWith this modification, the active_until field will be displayed in the list of subscriptions in the dashboard.
Sources:
'source': 'medgurus-learningplatform/app/dashboards/subscription_dashboard.rb'
'source': 'medgurus-learningplatform/db/migrate/20221021100112_fix_active_until_calculation_on_subscriptions.rb'
'source': 'medgurus-learningplatform/app/services/deactivate_old_subscriptions.rb'
'source': 'medgurus-learningplatform/spec/models/subscription_spec.rb'
'source': 'medgurus-learningplatform/db/migrate/20171107145726_create_subscriptions.rb'
PR from the real life team member
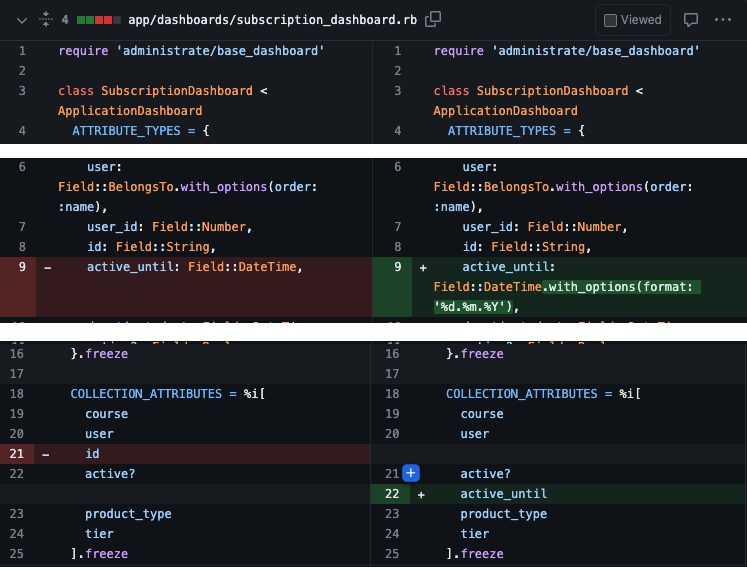
Granny RAGʼs suggestions were quiet correct. The change to the format was not mentioned in the ticket. This is why you need a human for this kind of tasks. But Granny RAG helped us a lot here.
How does it all work?
Granny RAG is a RAG system. That is short for Retrieval Augmented Generation. If you are looking for a quick intro, here is the nice video by Marina Danilevsky.
In essence, RAG improves the quality of LLM responses by enriching user prompts with relevant contextual information. It retrieves this information from an efficiently searchable index of your entire project, generated with the help of an embedding model.
Embedding models
Itʼs not easy to say something simple about the embedding process without being incorrect. Embedding models are models that generate a representation of the “meaning” sequence of text. This “meaning” is represented as a vector called “embedding”. It is a long array of numbers that represent semantic meaning within the given context.

Tokens with a similar meaning in the source document get embedding vectors “close to each other” by some distance measurement.
A suitable model will place expressions with similar meaning in similar spaces of its vector space. So subscription will be next to activation and active_until.
You can think of the process as hashing with a hashing function that understands the input.
Retrieval
Instead, when the user asks a question, we throw it into the same embedding function to get an index for it. With that, we do a lookup what sequences of text occupy a similar space in the memory.
There are multiple strategies for this similarity criteria. We will explore similarity in more depth in the second post of this series. For now, letʼs assume we found entries “close” to the index we got for the search term.
Each of those entries carries a piece of text and some metadata. The metadata tells us more about the source, e.g. which file it came from. Until now, we have build a more intelligent search function. It finds active_until even if you searched for end date. Something, a classic fulltext index would not find.
In an “old fashioned” information system, we would output those magical pieces of text and leave it to the reader to go through them, understand their meaning and evaluate their relevance.
“But wait”, you say, “are there not these new cool kids on the block, The LLMʼs™, that are brilliant at exactly that?”. You are right, this is exactly what RAG systems do.
Context
Attention: We will be simplifying heavily. If you would like to get a lightweight intro head over to this huggingface course, or this series of videos from three blue one brown.
It boils down to this: When LLMs generate, they find the next word, or gaps in a text. They take this a step at a time, a bit like friends finishing each otherʼs sentences.
Then, they look at the text created, including the new word, and compile the next word, and the next. Put differently, they try to find the piece of text or the character that is most likely to make sense in the previously generated context.
Here is an example for a prompt that uses RAG:
You are an assistant for question-answering tasks. Use the following pieces of
retrieved context to answer the question. If you donʼt know the answer, just
say that you donʼt know.
Use three sentences maximum and keep the answer concise. # (1)
--
Question: “What would I need to change to show the active_until date in the list
of subscriptions?” # (2)
Context: {context} # <- The RAG magic happens here
Answer: # (3)
A system prompt tells the LLM what is expected from it (1), then a question is specifying the task (2) and the “please fill in your answer here”-part (3) is what LLMs are used to work with.
LLMs do so, again, based on vector representations. Starting from a seed, often the system prompt, and the userʼs instructions.
The idea of RAG is that if you include facts that you researched into your prompt, the context for the generation is narrowed down significantly compared to a prompt that does not include those facts. Retrieval Augmented Generation is an effective countermeasure against hallucinations. It does not stop them, but makes them less likely.
Outline the Important Findings in your follow up
All LLM based systems hallucinate at some point. RAG helps to avoid that, but as you can see in 5. Follow Up, even Retrieval Based Systems stray from the truth at times. You can detect that because the information in 5. Follow Up does not align with the previous answers.
If this happens, it helps to outline the previous facts in the next prompt, as I did in 6. Follow Up:
...
“You said before that the
COLLECTION_ATTRIBUTESare responsible for the list ofSubscriptions(...)”
...
Mentioning previous findings in the new prompt amplifies them in the context. This steers the conversation in the direction you like and helps helps the LLM to let go of the hallucinations.
The Code
You can find the code on bitcrowdʼs GitHub, which is probably easier to read than going through the inline version here.
We will use LangChain, which is a Python library. There are also implementations of it in JavaScript and Elixir. We use Python to start with, because it is the common language for machine learning, so prototyping is easy. Once we know what we want, we will explore the Elixir way. So please make sure you have Python installed.
We use JinaAI embeddings, which is a very capable model that can be used locally under the Apache 2 licence.
Finally, you need Ollama, or any other tool that letʼs you run a model and expose it to a web endpoint. In the example, we use Meta's Llama3 model. Models like CodeLlama:7b-instruct also work. Feel free to change the .env file and experiment with different models.
Test Drive
You need some Ruby library that we can try out here. Letʼs go for Discourse.
Weʼre interested in the logic Discourse uses to prevent users from re-using an old, expired password and which files in the code are relevant for this. So we ask it:
How does Discourse keep track of which passwords a user already used? So that when changing their password, a user does not use the same, expired password again.
Granny RAG answers:
According to the context you provided, Discourse keeps track of which passwords a user already used by storing the old password hash and algorithm in the
user_passwordstable. This is done through the following mechanisms:
- The
user_passwordstable stores the userʼs previous passwords along with their corresponding salts and algorithms.- When a user changes their password, Discourse generates a new password hash using the new password, salt, and algorithm.
- Discourse then checks if the new password hash is already present in the
user_passwordstable for that user. If it is, it means the user has used this password before, and therefore, itʼs considered expired.By storing the old password hashes and algorithms in the database, Discourse can easily verify whether a user has used a particular password before and prevent them from using an expired password again.
This approach ensures that users cannot reuse the same password twice, even if they change their password multiple times. …

Without knowing all the details of Discourseʼs codebase, this seems a perfectly valid answer. It gives us a nice summary of the feature and an idea on where to go looking for the implementation in Discourseʼs otherwise overwhelmingly big codebase.
Wrap up
For our InfoServer Granny RAG we created a sophisticated search index for our codebase. This index allows us to infer meaning. We can now search for an answer by inferring the meaning of the question and retrieve relevant information by looking at what is close in the vector space.
We fed this information to an LLM to understand and prioritize the sources. We made the LLM create answers to our questions, based on its training data and the information retrieved.
So with a few, off-the-shelf, open source components, we manage to get expert knowledge about our code base, and get it delivered to us by our friendly LLM companion, hosted on our own premises.
How is this different from Copilot, Duo and friends?
If you ask Granny RAG a question, it can draw information from the whole codebase. It is able to incorporate all kinds of documents, and can be extended to incorporate additional data-sources. Granny RAG operates on resource effective, local LLMs.
No data needs to leave your control.
The scripts that ingest and embed your data and code can be specific to your needs - as is your codebase. That way, you can even specify what should, and what should not, find its way into your RAG knowledge base.
Copilot and GitLab Duo have a much narrower angle of vision. Their context is primarily the opened files of the editor, or the PR. That means, once you know where to look, they can be helpful. Both to you and their creators, which can (and probably will) use some data to improve their models. Even if, per contract, your data and code should not be shared with GitLab or Microsoft, you lost all control once your data leaves the premises.
If you set theses concerns aside, you still have little control about what makes its way into the LLMs that are hosted on remote servers.
Here again, Granny RAG is different. You can collect data from usage and reactions, and you can use that data to train both, LLM and embedding model, on your data and needs.
That way, new arrivals in your dev team get an assistant that is steadily improving. Granny RAG can integrate into a Slack channel to provide a first opinion, and take feedback from the more seasoned developers to improve.
All in all, Granny RAG is a concept that can (and should) be adopted to your use-case and needs. Itʼs not a subscription you buy, but a technique your team learns to master. You invest in consulting or learning time, and you get control and excellent knowledge about the core of your business logic.
Try it yourself!
It is really easy! Just clone our repo, follow the README and tell the script where to find your codebase:
CODEBASE_PATH="./path-to-my-codebase"
CODEBASE_LANGUAGE="ruby"
We kept the scripts basic, so that they are easy to understand and extend. Depending on your codebase, the results might not always be perfect, but often surprisingly good.
Outlook
In this introductory post, we saw what a little off-the-shelf system can achieve. Itʼs already impressive, and it only uses local models, namely Llama3 and JinaAI Code.
You will find that this off-the-shelf solution is lacking precision in some use cases. To improve this, we will explore how changes in the parsing, chunking and embedding strategies will change performance in the next episodes of this blog post series.
Or, if you canʼt wait, give the team at bitcrowd a shout via granny-rag@bitcrowd.net or book a consulting call here.
