What is legacy code?
Sometimes that's the fifteen-year-old monolith. Sometimes it's the service that grew complicated faster than the team could keep up with. Sometimes it's that project that started as a shortcut and turned into a roadblock. Legacy code has been exposed to real world demands long enough to gather fixes for edge cases we are not aware of anymore.
And — increasingly — sometimes it's the repo your CEO vibe-coded last weekend and that they proudly present on Monday. It runs. Now you have to own it.
Legacy software is the code we lost confidence in
That last category is genuinely new and growing fast. Code written once, never reviewed, tested a bit, deployed one day. Or, worse, released as a library and never maintained after that.
A new kind of technical dept has evolved: "The code we should review thoroughly one day."
"Can we rewrite this?"
The actual problem is not the writing of the new code, but the discovery of what the old code does, and the certainty that the new one does the same thing.
We've been building two small Elixir tools to help with both halves of that problem.
- Surveyor scans a codebase in any language and produces an architectural model.
- Assay runs the same plain-text behavioral specs against both the legacy and the rewrite, so you can prove they behave the same.
Together they cover the workflow: Figure out the structure, capture the behavior, rewrite, prove the rewrite works.
Surveyor produces an automatically verifiable behavioral specification of a legacy system.
How we got here
Before going into either tool, it's worth walking through the shape of the problem. The picture builds up step by step, and the final diagram only makes sense once you've seen the holes in the earlier ones.
What we don't want
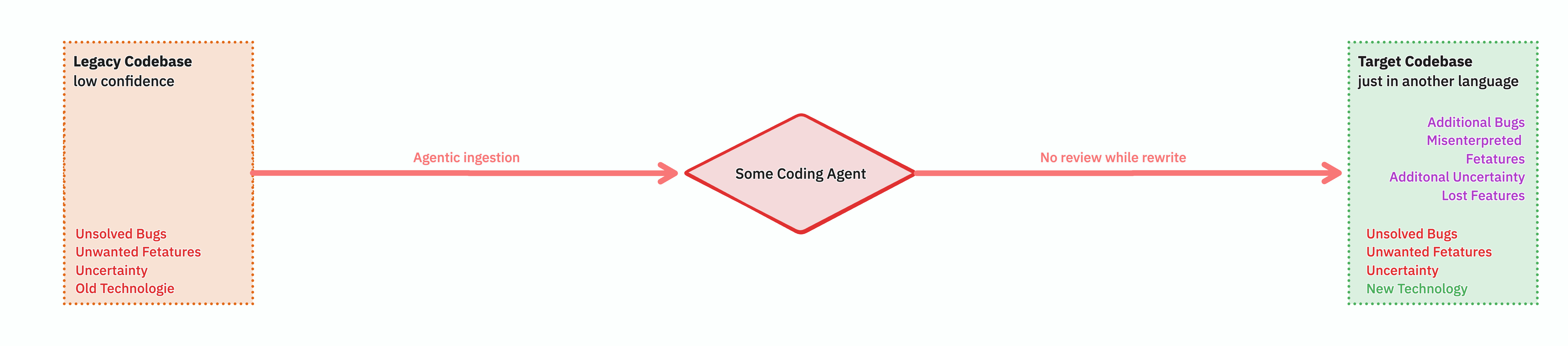
Point an agent at a legacy codebase, ask it to produce a new one, hope for the best. Call it "the Claude zombie rewrite." You end up with a target codebase that nobody understands either, plus a generation gap between the old assumptions and the new. What has the agent overlooked, misunderstood, assumed? A black box gets replaced with a different black box. That is not a rewrite, that is a transcoding.
What we want instead
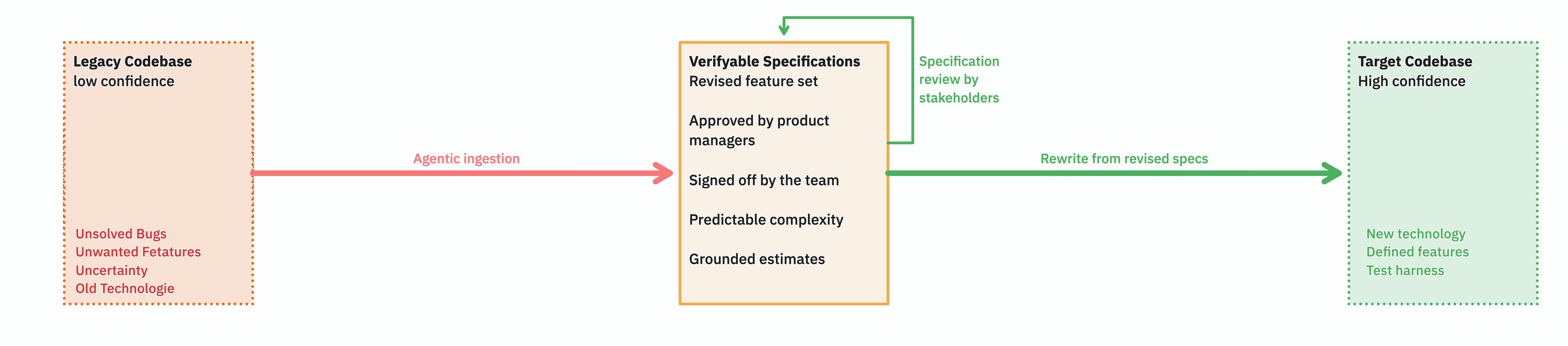
The valuable artifact in the middle is not new code — it's a readable specification of what the old code actually does. Plain text, human-reviewable, version-controllable. The kind of thing you need when you want to ask the product owner if a feature is really wanted that way. - Or if it is just a legacy quirk.
If you have it, you can use it for estimates. It can be your map to plan the implementation and might even give you a hint about that stakeholder that you might have forgotten about otherwise.
Organised and illustrated
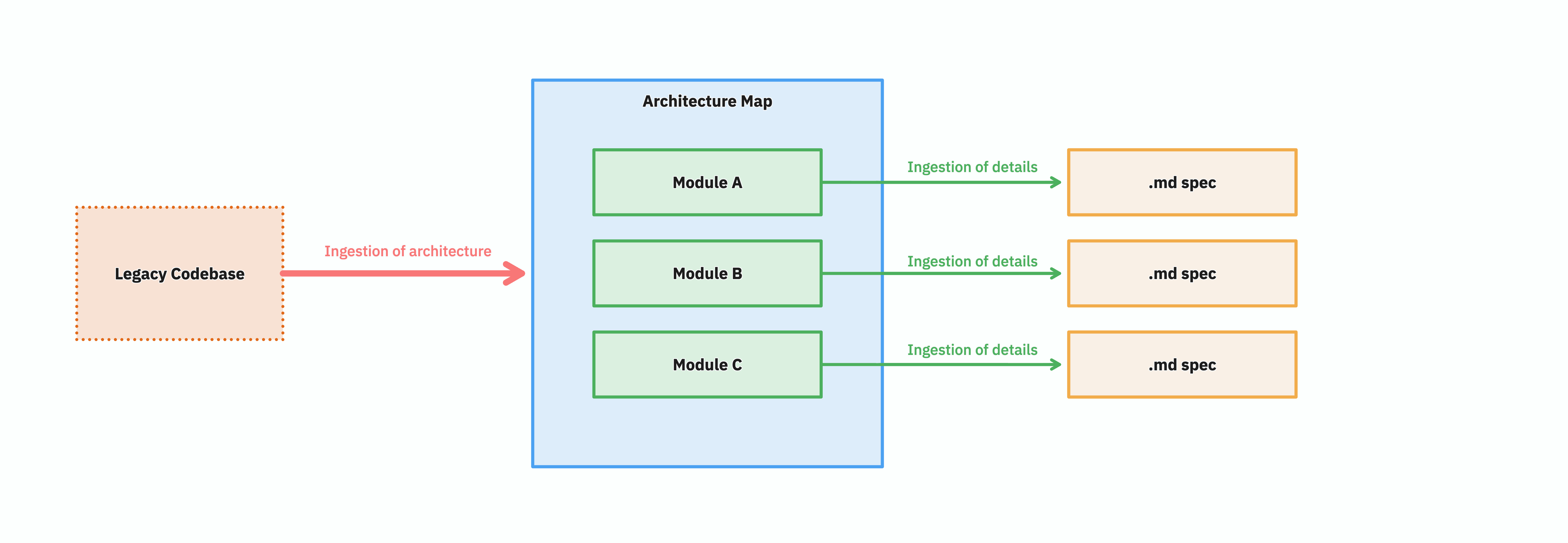
A single big text file describing a whole legacy system is only useful for very small projects. You want the spec broken down by module — by bounded context — and the modules themselves arranged on a map of the architecture. Once each module has its own spec associated to it, two things become possible: you can divide the work, and you can reason about coverage.
Job done! Or is it?
We now have and organised map of the system and a set of specifications. We have an overview, and the details. We could now talk to the stakeholders, the development team, and set to work.
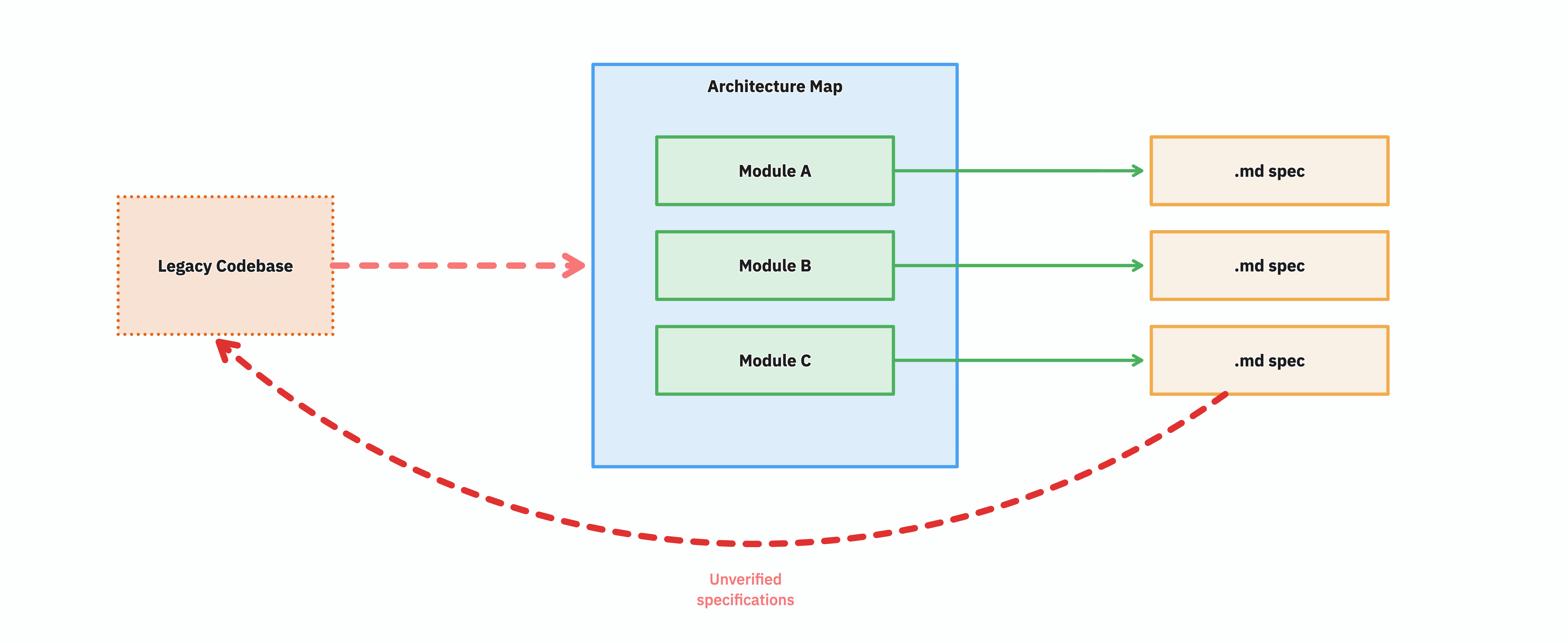
However, we have not yet verified our findings.
What we are looking at is not yet a specification of the legacy system — it is a speculation of the legacy system. A document that claims to describe what the code does, written by reading the code (or by asking an LLM to read the code). Plausible, well-organised, reviewable. But unverified.
1. Verifiability
This is speculation as specification, and it's the trap most "let's document the legacy system" projects fall into. A Word document of "what the system does" can be worse than no document at all, because people start trusting it. But even if the specification is done as a group effort by all stakeholders involved, and is thoroughly verified, it still lacks one critical property:
2. Reproducibility
What we actually want is a verifiable specification: Not "verified once," but verifiable on demand, any time someone asks the question. You could verify a paper spec by hand, of course — sit down, read it, run the system, tick off the scenarios — but manual verification is expensive enough that it gets done once at sign-off and never again.
A verification you don't actually do is verification that doesn't exist. And unless the legacy codebase is a museum exhibit, it's a moving target:
The team is still shipping fixes, the system is still drifting, and a paper spec written on Monday is no longer accurate by Friday.
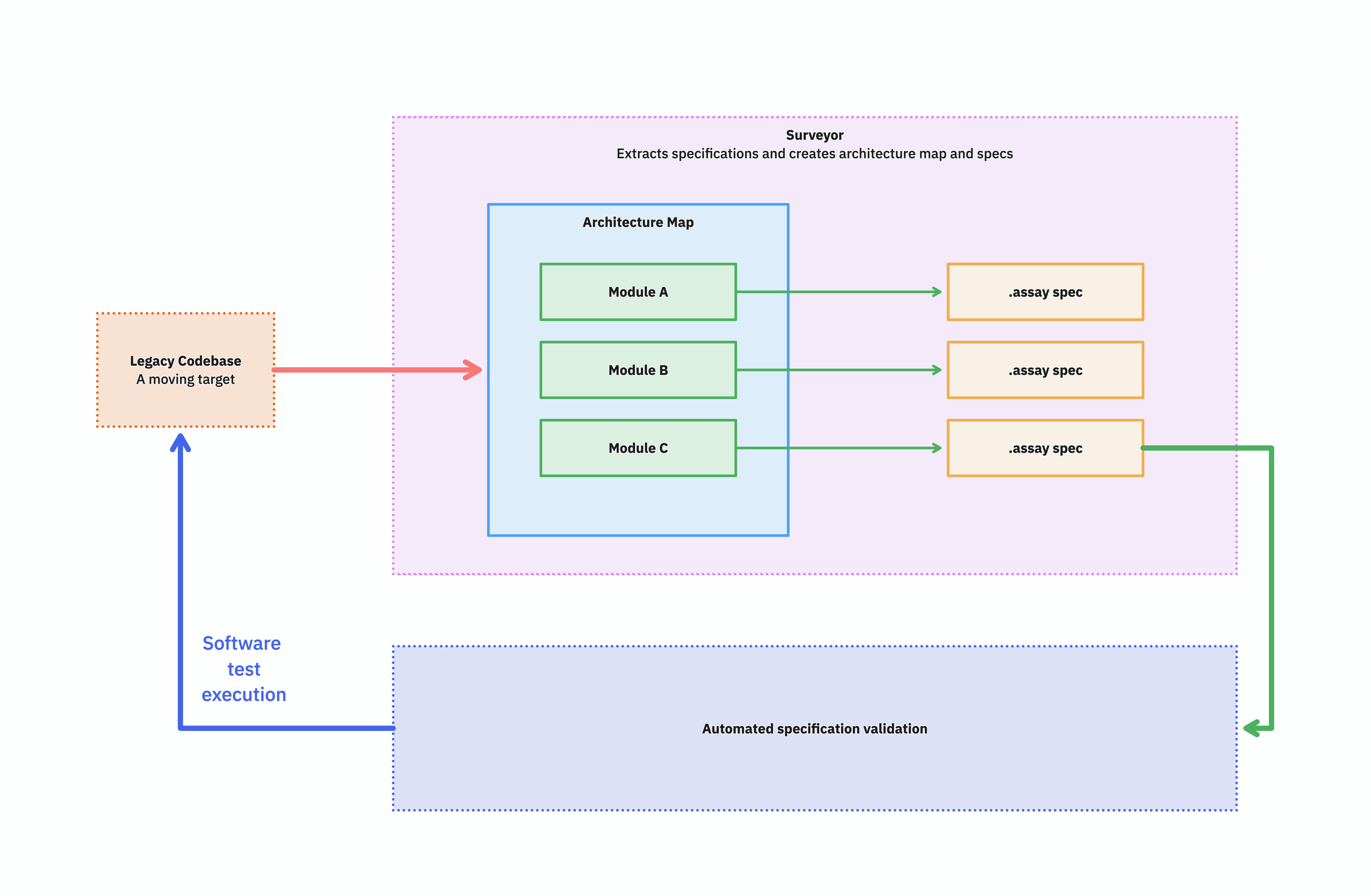
Runnable specs
The fix is to make the specs executable — to wire them into something that can run them against the actual legacy system, on demand, and tell you whether they still hold.
That is the move from speculation to verifiable specification: not a one-shot audit, but a button you can press on every commit, every nightly, every time anyone asks "is this still true?"
A green run proves the spec is still true. A red run is a useful signal: either the legacy drifted, or your spec was wrong. Either way, you find out before the rewrite, not during it.
That magic is Assay
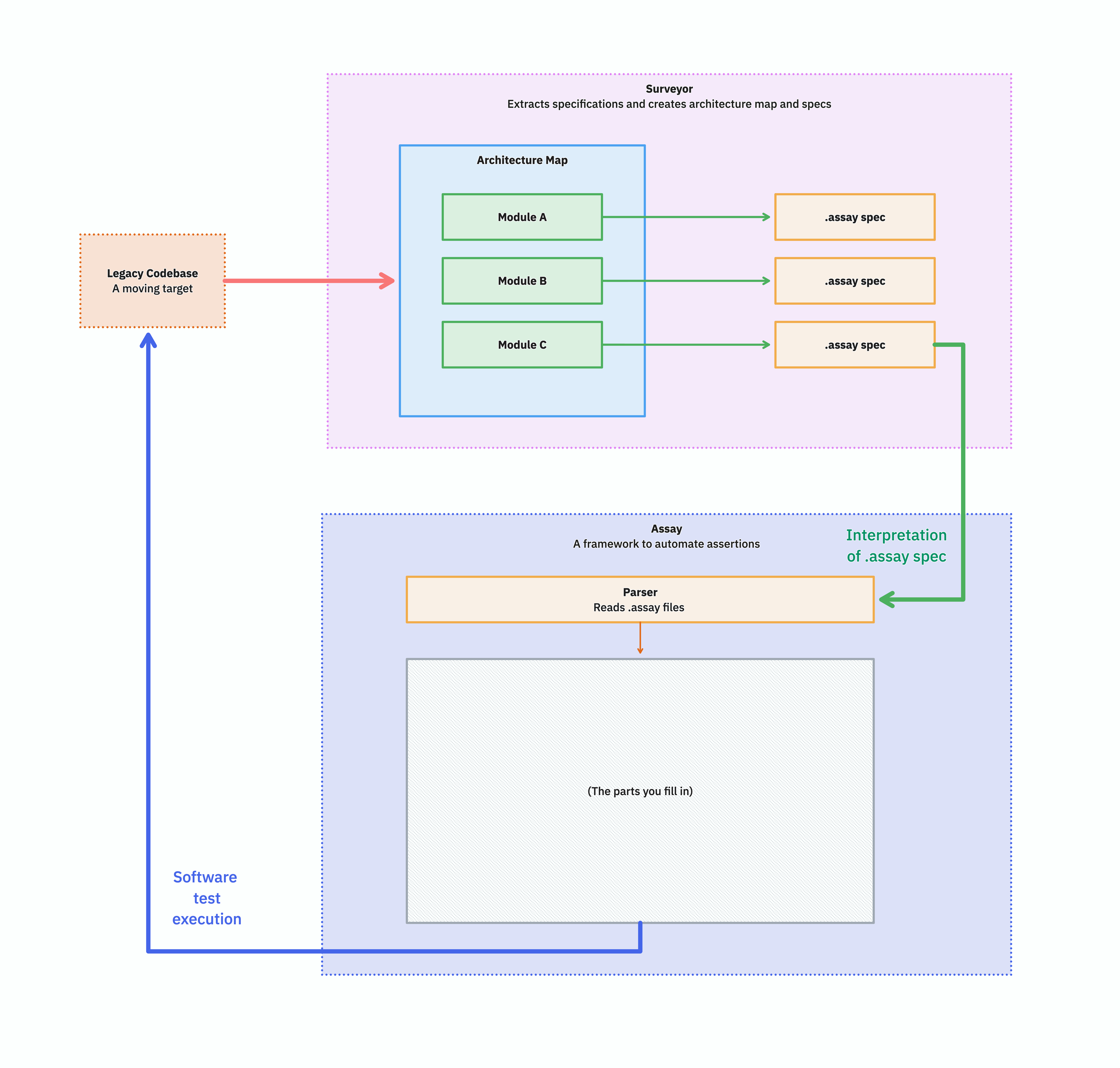
Assay is the runner.
It parses the .assay specs Surveyor produced, matches each step against bindings you write, and exercises the real legacy system through whatever interface it actually exposes — HTTP, CLI, message queue, file drop, whatever.
The framework is small.
The runtime contract is "your bindings + your assertions + a deterministic runner."
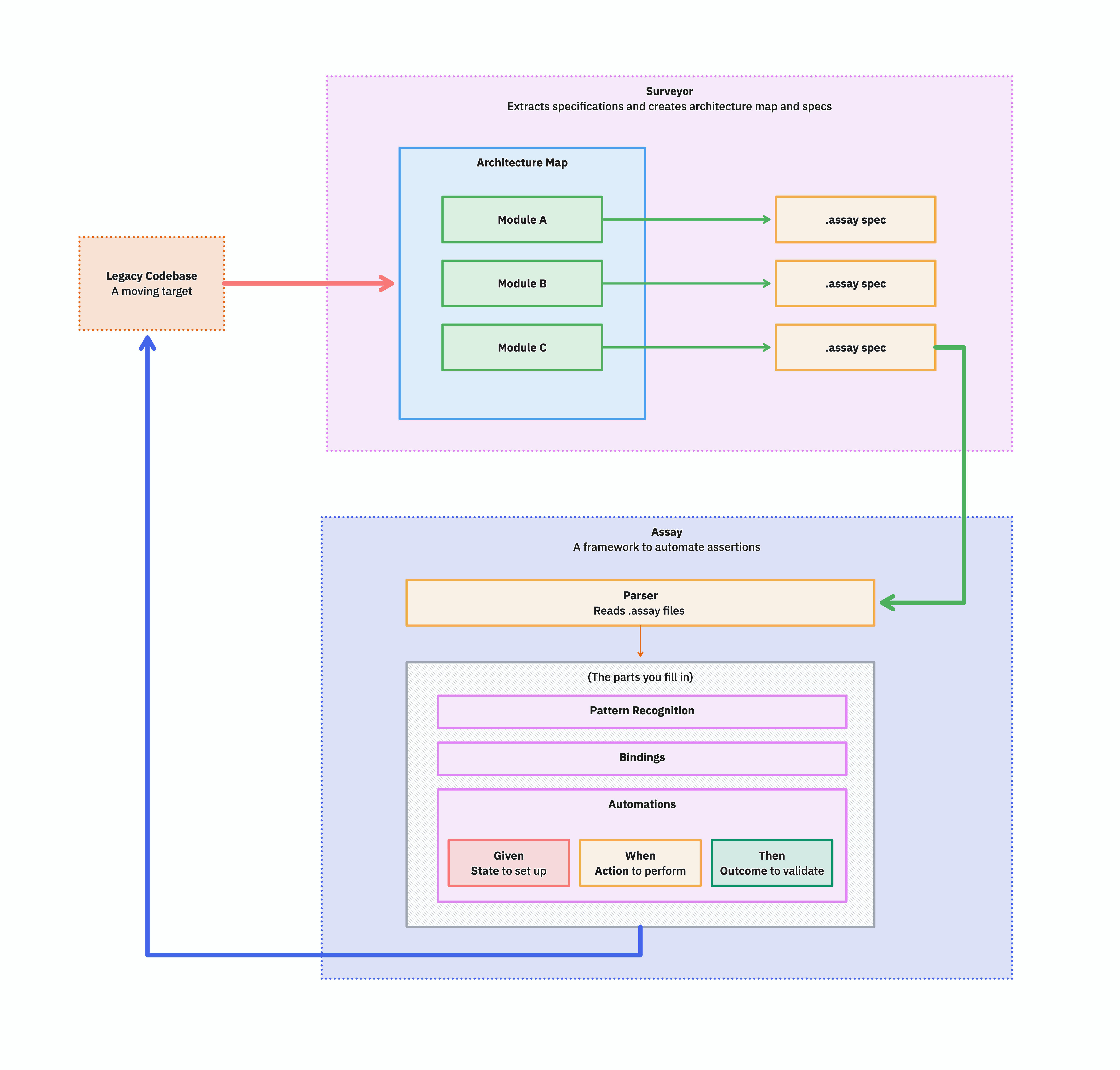
The systemic approach
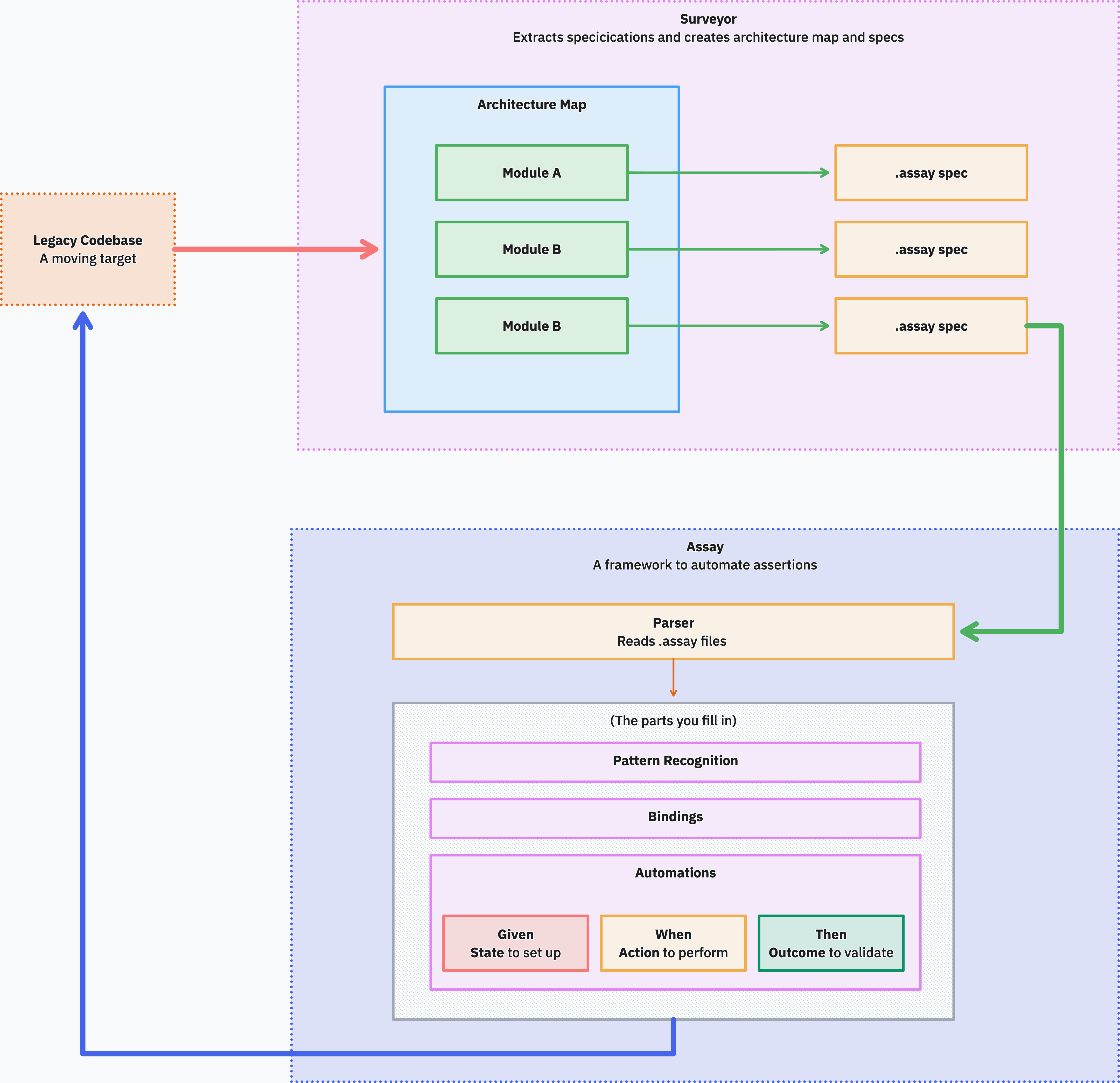
Open up that "parts you fill in" box and you find the actual surface area of work: pattern recognition for step matching, a binding per target system, and Given/When/Then automations for setup, action, and verification.
The end state has a property that nothing in the earlier pictures had: the problem space has been dissected into manageable pieces. Architecture, behavior, target adapters, assertions — each is small, each can be reviewed independently, and each can be picked up by a human or an agent without having to hold the whole system in their head at once.
That's the goal of the toolkit. Everything below is the detail of how each piece is built.
Surveyor — discovering the architecture you inherited
Surveyor is a Mix project that takes a path to a codebase and produces a Structurizr DSL workspace file. It runs in three phases mapping to the C4 model: C1 (system context), C2 (containers), C3 (components per container).
Crucially, Surveyor does not parse code. There are no language-specific parsers, no AST walkers, no fragile grammar files for thirty different ecosystems.
It scans the filesystem to identify what's there — languages, frameworks, project files, entry points, deployment manifests — and then feeds meaningful chunks to an LLM. That sounds trivial, but is the same mechanism that commercial coding agents use when they analyse your code.
Surveyor's intelligence is in the prompts and the chunking, not in a stack of half-broken language adapters.
The CLI is interactive at every phase.
$ surveyor ./legacy-monolith --phase c1
Phase 1 — System Context
Scanning codebase...
Querying LLM...
System: "Order Management System"
Description: Manages the full order lifecycle
Actors:
✓ Customer — places and tracks orders via Web UI
✓ Warehouse Staff — manages fulfillment via Back Office
? Admin — found references in auth config (confidence: low)
External Systems:
✓ Stripe — payment processing (REST API)
? SendGrid — found API key in config (confidence: low)
[a]ccept [e]dit [r]etry with more context [q]uit
>
The LLM is asked to flag uncertainty.
Anything tagged confidence: low shows up with a ? and a short reasoning string for human review.
That's not just nice ergonomics — it's the bit that makes the tool trustworthy.
An LLM that confidently invents a PaymentReconciliation container that doesn't exist is worse than no model at all.
An LLM that says "I see a SENDGRID_API_KEY in .env.example but no Sendgrid client in the source, please confirm" is doing the right kind of work.
Each phase is resumable.
Results are saved as JSON in ./surveyor/, so a thirty-container system doesn't have to finish in one sitting.
You can hop in, accept C1, take a break, come back tomorrow, and resume at C2.
The end product is a workspace.dsl you can render in Structurizr.
But more importantly, it's a workspace.dsl whose components are decorated with assay.specs and assay.schema properties, pointing at the behavioral specs and the domain schemas for each bounded context.
orderLifecycle = component "Order Lifecycle" "Orders" "Bounded Context" {
properties {
"assay.specs" "specs/order-lifecycle"
"assay.schema" "schemas/order_lifecycle.ex"
}
}
DDD pattern annotations from the LLM (customer-supplier, anticorruption-layer, …) ride along as properties on the relationship.
Every component gets assay.specs and assay.schema properties — the contract the next tool reads from.
Examples
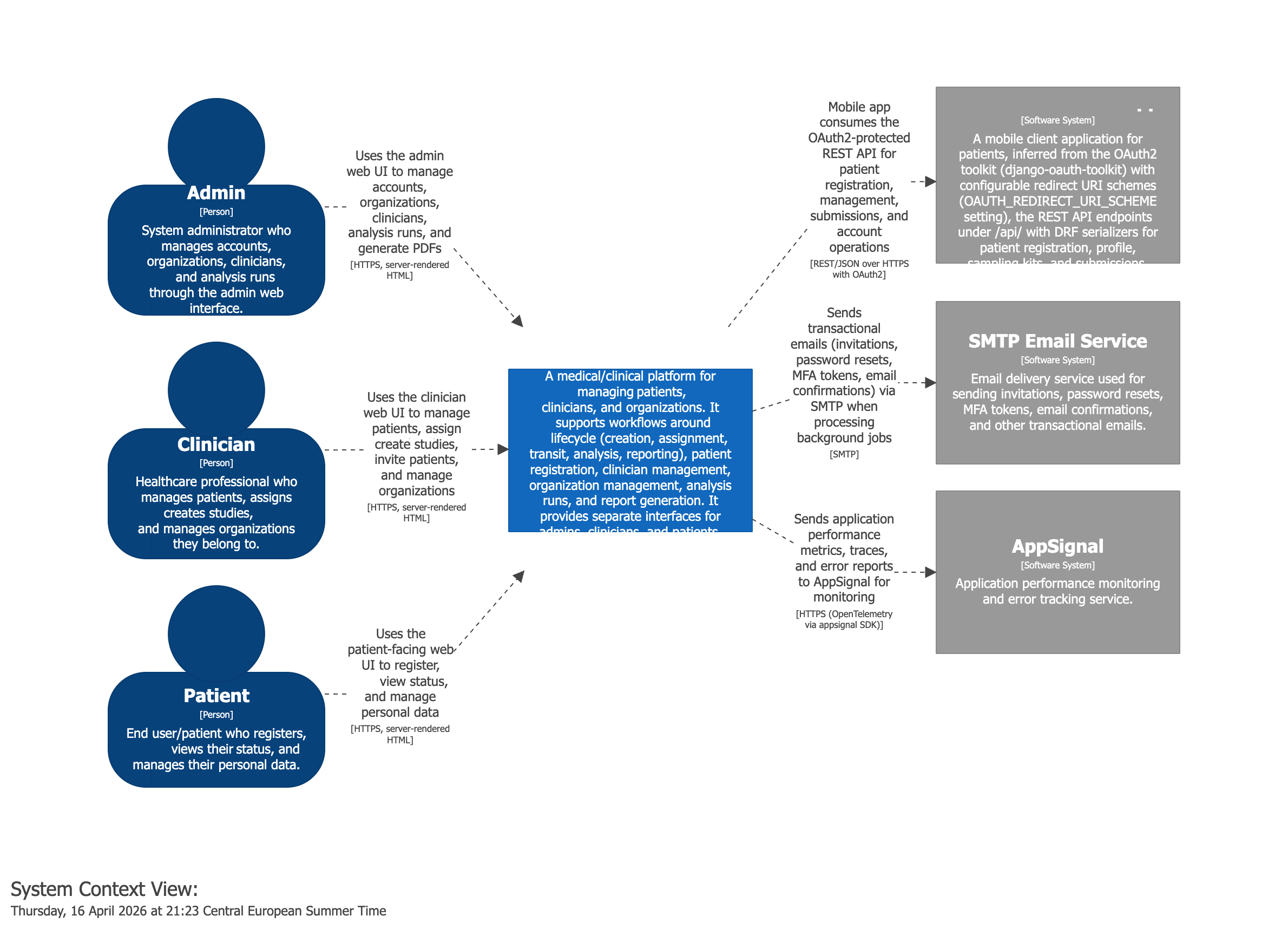
The System Context of a Medical Application
Surveyor identified the actors and the external systems of the application. Without knowing the code, we would already know which actor types there are
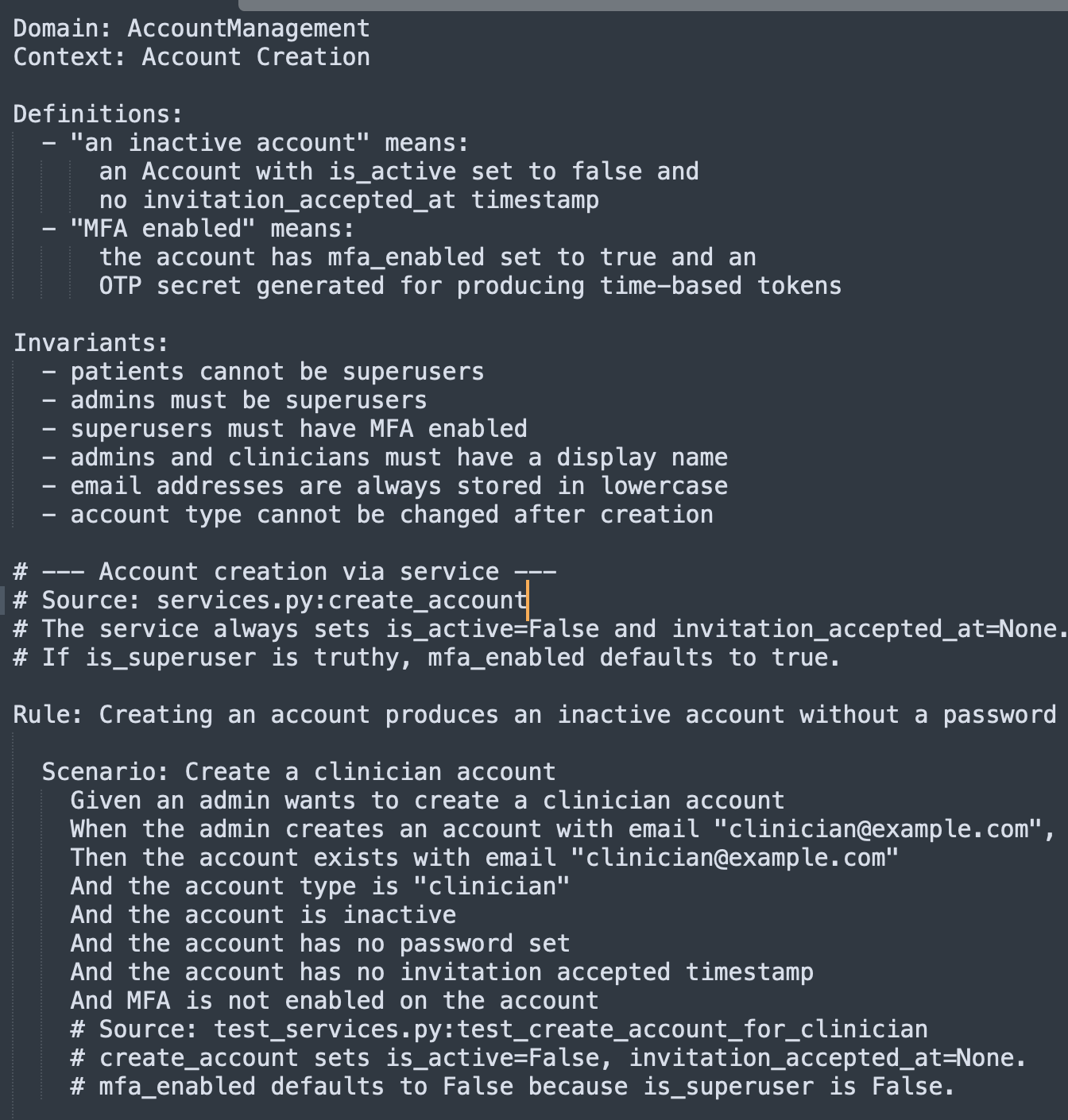
An example of an assay spec created in the second phase:
Assay — proving the rewrite behaves the same
Assay is a minimal behavioral spec runner. Specs are plain text and look like this:
Component: [orderLifecycle] Order Lifecycle
Context: Order Placement
Definitions:
- "a valid customer" means:
a Customer with status Active, verified email,
and a credit limit greater than zero
Invariants:
- total must not exceed customer credit limit
- at least one line item required
Rule: Customers can place orders for in-stock items
@critical @phase-1
Scenario: [OL-001] Place a simple order
Given a valid customer "Alice" with credit limit €10,000
And product "Widget" is in stock with 50 units available
When Alice places an order for 3 units of "Widget"
Then the order status becomes "Placed"
And stock for "Widget" is reduced to 47 units
The bracketed [orderLifecycle] is a workspace.dsl identifier — the same identifier Surveyor wrote into the architecture model.
The bracketed [OL-001] on the scenario is an optional free-form id that survives across rewrites of the spec text and lets you cross-reference from tickets or audit trails.
If that looks like Cucumber or Gherkin, it does — with one large difference. There is no glue layer, no abstraction over what kind of system you are testing, no framework opinions about HTTP, databases, or browsers. The bindings are just Elixir.
defmodule Targets.Legacy.OrderLifecycle do
use Assay.Binding, component: "orderLifecycle"
@base System.get_env("LEGACY_API_URL")
step :given, ~r/a valid customer "(?P<name>.+)" with credit limit €(?P<limit>[\d,.]+)/ do
{:ok, resp} = Req.post("#{@base}/test/customers", json: %{
name: params().name,
credit_limit: parse_money(params().limit),
status: "Active"
})
assign(customer_id: resp.body["id"])
end
step :action, ~r/.+ places an order for (?P<qty>\d+) units? of "(?P<product>.+)"/ do
{:ok, resp} = Req.post("#{@base}/orders", json: %{
customer_id: var(:customer_id),
lines: [%{product_id: var(:product_id), quantity: to_int(params().qty)}]
})
assign(order_id: resp.body["id"], http_status: resp.status)
end
step :expect, ~r/the order status becomes "(?P<status>.+)"/ do
{:ok, resp} = Req.get("#{@base}/orders/#{var(:order_id)}")
assert resp.body["status"] == params().status
end
end
A binding is just a module that brings whatever it needs — Req for an HTTP API, AMQP for a message broker, System.cmd for a batch processor, File for a directory-watching pipeline.
Assay itself does not ship an HTTP client or a database adapter.
The framework provides parsing, step matching, scenario lifecycle, and assertions; the rest is your code. That's what makes the same spec runnable against an HTTP API, a CLI tool, a batch job, or a message queue, depending on what the legacy system happens to be.
🚀 Would you like to run this on your legacy codebase? Sign up for early access! Count me in!
The crucial property is target swappability:
assay run specs/order-lifecycle/ --target legacy
assay run specs/order-lifecycle/ --target new
Same specs. Different bindings. Different systems. The legacy binding hits the old SOAP API; the new binding hits the new Phoenix endpoint. If both go green, the rewrite is behavior-equivalent for the things the spec covers — which, after a few months of writing specs, is most of the things that matter.
There is no separate .exs file generated from the specs.
The runner parses .assay files, matches each step against a regex on a binding function, executes them, and prints pass/fail.
That's it.
How Assay actually works
The runtime is around six hundred lines of Elixir. Five design choices do most of the work.
A two-pass parser
The first pass lifts triple-quoted doc strings out of the file (so the line tokenizer doesn't have to reason about them). The second pass dispatches on the first keyword on each line.
def parse_string(content) do
{filtered, doc_strings} =
content
|> String.split("\n")
|> Enum.with_index(1)
|> extract_doc_strings()
Process.put(:assay_doc_strings, doc_strings)
filtered
|> Enum.reject(fn {line, _} ->
trimmed = String.trim(line)
trimmed == "" or String.starts_with?(trimmed, "#")
end)
|> parse_lines(%Spec{})
end
Output is a plain %Spec{} struct. No AST nodes, no string interpolation.
The step macro generates real module functions
Each step :given, ~r/.../ do ... end call expands into a uniquely-named function plus a %StepBinding{} record on an accumulating attribute.
defmacro step(type, regex, do: block)
when type in [:given, :action, :expect] do
fn_name = :"__step_#{:erlang.unique_integer([:positive])}__"
quote do
@assay_steps {unquote(type), unquote(regex), &__MODULE__.unquote(fn_name)/0}
def unquote(fn_name)() do
unquote(block)
end
end
end
At compile time, __before_compile__ exposes __steps__/0 and __component__/0 for the runner to read.
There is no string codegen, no eval — just normal Elixir function definitions.
Component-scoped step matching
Anyone who has used Cucumber has hit the global step-definition problem: the same step text means different things in different contexts, but Gherkin treats step definitions as one shared namespace. Assay scopes bindings by component:
defp run_spec(spec, bindings, target, tags, exclude_tags) do
component_bindings =
Enum.filter(bindings, fn b -> b.component == spec.component end)
# ... run each scenario against component_bindings only
end
This is the direct reason Surveyor and Assay use the same identifier convention. The architecture model and the spec runner share a vocabulary, and step text never collides across bounded contexts.
Pre-check, then execute
Before running any step, the runner walks the whole scenario and finds a binding for every step. If anything is unbound, the scenario fails before any side effects.
def run_scenario(scenario, bindings) do
matched_steps =
Enum.map(scenario.steps, fn step ->
case find_binding(step, bindings) do
nil -> {:unbound, step}
binding -> {:bound, step, binding}
end
end)
if Enum.any?(matched_steps, &match?({:unbound, _}, &1)) do
%ScenarioResult{status: :error, error: "Unbound steps found"}
else
execute_matched_steps(scenario, matched_steps, bindings)
end
end
This is what stops a scenario from running half its Givens, hitting an unbound When, and leaving a dangling test customer in the database.
Per-scenario state in the process dictionary
Each scenario gets a fresh context — a tiny module that stores variables, params, doc strings, and data tables in the process dictionary.
def init do
Process.put(@vars_key, %{})
Process.put(@params_key, %{})
end
def get_var(name) do
Process.get(@vars_key, %{}) |> Map.get(name)
end
def set_vars(keyword) do
vars = Process.get(@vars_key, %{})
Process.put(@vars_key, Enum.into(keyword, vars))
end
The runner can save/0 and restore/1 the snapshot, which is how Assay tests itself by running its own .assay specs through itself in the same process.
There is no plugin system, no dependency injection, no scenario hooks beyond cleanup.
Adding any of those would push complexity into the framework and out of the binding, which is the wrong direction.
The framework exists to be small enough that you can read it on a Friday afternoon and trust it on Monday.
How they fit together
The flow is straightforward and it maps onto the five phases laid out in the Assay handbook.
- Discovery (Surveyor). Run Surveyor against the legacy codebase. Walk through the C1/C2/C3 output interactively. Edit, retry, accept. Produces
workspace.dsl. - Behavioral extraction. For each component in the model, write
.assayspecs and an Elixir schema. Theassay.specsandassay.schemaproperties on every Structurizr component tell you exactly where they go:specs/<context>/andschemas/<context>.ex. - Validation. Write bindings against the legacy system in
targets/legacy/. Runassay run specs/ --target legacy. Iterate until green. You now have a verified, executable specification of the legacy system's behavior. - Stabilization. Review what's covered, what's missing, what's flagged as ambiguous. Get sign-off on scope.
- Rewrite. Build the new system. Write bindings against it in
targets/new/. Runassay run specs/ --target new. When that's green, the rewrite is done — at least for the surface area the specs cover.
The reason the two tools sit next to each other is that the architecture model is what gives the spec work structure.
Without a model, "write specs for the legacy system" is an open-ended task with no obvious stopping point.
With the model, every component has a specs/ directory and the question becomes "is each context's behavior covered?"
That's tractable.
🚀 Would you like to run this on your legacy codebase? Sign up for early access! Count me in!
The cross-target story is what makes the rewrite verifiable.
The same parsed .assay scenarios are dispatched, step by step, through two different binding modules at two different points in the project's life:
Same spec, two bindings, two systems. The runner doesn't know or care which target it's dispatching to — that's the property that makes the rewrite a measurable thing rather than a leap of faith.
Four audiences, one artifact
Four very different parties end up reading — or executing — the same .assay file: the product owner, the developer, the coding agent, and the test runner.
The interesting observation is that they don't conflict on content — they conflict on form.
Product owners want to know what the system does in business terms, what would break if you changed X, and where the risk lives. They don't want UML. They want to read scenarios in their domain vocabulary, in plain language, and trust them.
Developers want to know how the system is structured, where the seams are, and what invariants they mustn't break. And — crucially — they want the documentation to be wrong less often than the code is. The moment docs lie, developers stop reading them.
Coding agents want machine-parseable, unambiguous, addressable artifacts with stable identifiers.
They want to be able to say "the assertion at assay://orderLifecycle/order-placement/OL-001/step-3 failed" and have that mean something durable.
They want types, schemas, and graphs they can traverse.
Automated tests want executable bindings — the layer Assay provides — and they want failures that point back to the spec, not just to a line of code.
Same facts, four presentations.
The .assay file gives the product owner readable scenarios in domain language.
The workspace.dsl plus the schema modules give the developer the structural truth.
The bracketed identifiers (Component: [orderLifecycle], Scenario: [OL-001]) give the agent its stable addresses.
The runner turns the whole thing into a regression suite.
None of these audiences is asked to read the others' representation; they all read the same spec, surfaced at the level of detail they need.
Where the LLM lives, and where it doesn't
A reasonable question at this point: with all the recent enthusiasm for LLMs, why isn't more of this LLM-driven?
The split is deliberate.
Surveyor uses an LLM because architectural discovery is genuinely a language task — you're reading config files, route definitions, deployment manifests, dependency lock files, and inferring "this is the API, that's the worker, that's the read model." That's exactly the kind of fuzzy, evidence-weighing job an LLM does well, especially when you tell it to flag uncertainty rather than guess.
Assay does not use an LLM at runtime. The runner is deterministic: parse the spec, match the regex, execute the binding, assert. A behavioral spec that sometimes passes and sometimes does not, depending on which model variant happened to answer, is not a spec.
LLMs are very welcome on the authoring side — drafting .assay files from legacy source is a great agent task, and the handbook has explicit guidance for coding agents about how to do that without inventing behavior.
But the green/red signal at the end has to come from a deterministic runner, or it is not really a signal.
🚀 Sign up for early access: Count me in!
How you use them on a project
In practice, the first day of a legacy rewrite looks something like this:
- Clone the repo. Run Surveyor with
--phase c1to get the system in context. Discuss the actors and external systems with the client — this alone surfaces "wait, who is the Admin role?" conversations that would otherwise happen three months in. - Run
--phase c2to map containers. This is where you discover the data plane that nobody documented, the cron job running on a forgotten server, the queue that two services share. Surveyor flagsconfidence: lowitems; the human resolves them. - Run
--phase c3per container. By the end you have aworkspace.dslthat is, for the first time in the project's history, an accurate picture of what is deployed. - Pick the highest-risk bounded context. Read the legacy source. Draft
.assayspecs for its behavior. Write a legacy binding. Run it. Iterate until green. - Repeat per context, in priority order, until coverage is good enough to start the rewrite.
- Build the new system, one bounded context at a time, with
targets/new/bindings going green as each context comes online.
The thing both tools are optimized for is the same: making the work legible.
A legacy rewrite is a long project with shifting personnel and a nervous client.
Both Surveyor and Assay produce artifacts — a workspace.dsl and a directory of .assay files — that survive turnover, show progress, and that the client can actually read.
Friendly User Trial
Our next step is to test Surveyor on real world projects. We want to find out if the artefacts it produces are already helpful or need to be extended. This is where we need your help:
If you have a legacy system staring you down and a rewrite on the roadmap, get in touch. We would love to hear from you!

