
In my recent blog post on ChromicPDF I (needlessly) bragged about how fast it generates PDF in comparison with the most popular puppeteer-based alternative libraries in the Elixir ecosystem. Consequently, a few of my co-workers were eager to challenge this claim, asking for numbers to prove it. In this post, Iʼm going to back up my statements with benchmarks.
PDF throughput
Measuring performance is hard, especially when your benchmark subject has a number of jittery components such as external OS processes. To not trip over common pitfalls, using a battle-tested benchmark solution like Benchee is a good idea.
The benchmark has a fairly simple setup: No parallelism, 10 seconds warm-up, 60 seconds measurements. The “short” input is a short paragraph of lorem ipsum text that fits on a single page, while the “long” input is the same paragraph duplicated 500 times, resulting in roughly 20 pages of PDF output. All contestants write the PDF to a temporary file and read the input from an in-memory HTML template. In case you would like to run these tests on your own, please see the code in its repository at Github.
The competitors are the two by far most downloaded PDF libraries on hex.pm: pdf_generator and puppeteer_pdf. Both make use of Googleʼs puppeteer library to launch and remote control a Chrome process. Just to recap, puppeteer is a JavaScript wrapper around the Chrome “DevTools” API, which allows to access developer interfaces within Chrome, which among many other things can open browser tabs, navigate to URLs or retrieve PDF prints of pages. ChromicPDF does not use puppeteer but instead implements a basic client for the “DevTools” protocol in Elixir.
As a disclaimer, please note that the following test isnʼt fair and not actually comparing the efficiency of the code in the used libraries. Instead, it simply demonstrates how having a background Chrome process in stand-by results in a far lower time needed for PDF printing than what can be achieved by spawning a new Chrome instance for each PDF. Still, the effects it has on “PDF throughput” are dramatic enough to display them here.
(Side note: If either of the competiting libraries has an option to re-use the browser process for multiple operations and I just didnʼt find it, my apologies. Please consider this a comparison of the approach rather than a comparison of the libraries.)
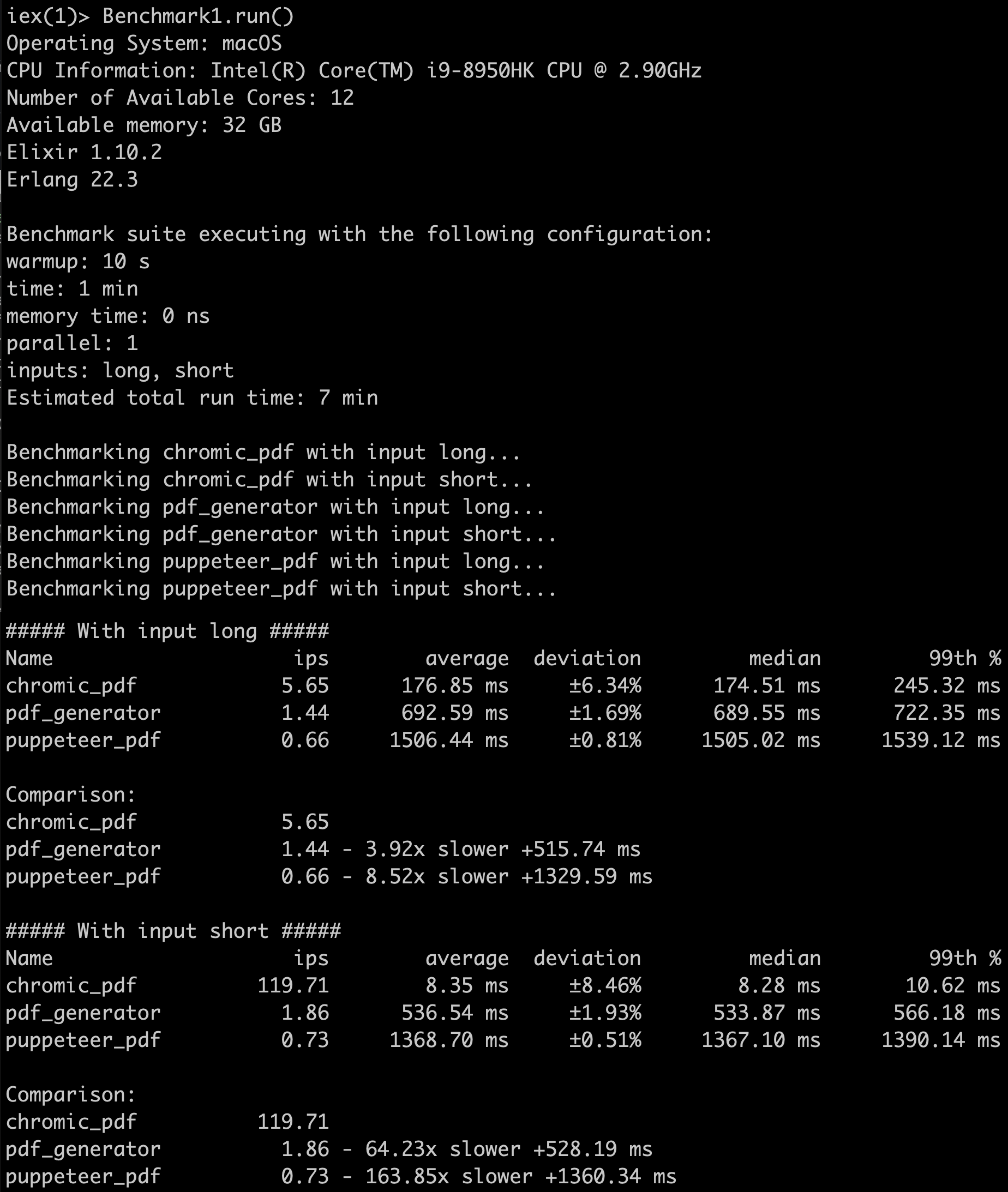
When the input is simple and does not stretch multiple pages, ChromicPDFʼs throughput is considerably ahead of the alternatives. However, this is largely due to the fact that both libraries spawn a new Chrome instance in each of these function calls. In fact, this beautifully shows in the data when we compare the “long” and “short” input of ChromicPDF and pdf_generator: While pdf_generator has an average runtime of 537ms per call for the short input, it clocks in at 693ms for the long input. ChromicPDF, with the short input zooming by in 8ms per call, takes approximately the same penalty of 150ms when printing the long input. Apparently the overhead of spawning and killing a Chrome instance in each call becomes a less dominant factor for more extensive input data. From these numbers one could estimate this overhead at roughly half a second.
There are a lot of blind spots in the setup of this benchmark. For instance, I did not investigate how much impact more complex HTML templates have on the rendering performance. A large template with lots of styles and graphical elements is likely to result in a longer rendering time, further reducing the advantage the background Chrome process has in the data above.
Yet, the data should sufficiently back up the claim in the announcement post. Not the library in itself is faster than others, but keeping the browser around as a background process has a significant performance advantage over alternative solutions. With it, however, come other considerations, some of which Iʼd like to further examine in the following.
Parallelism
In the process of creating the benchmark above I had enough time to play around with ideas on how to best evaluate ChromicPDFʼs performance with “tab-level” parallelism. By default, ChromicPDF currently spawns five browser tabs in its background Chrome process, a number which seems to be in need of justification, and perhaps a revisitation as well.
While Benchee would have been perfectly suitable for measuring PDF throughput in a parallel setup as well (with its parallel option), I threw together a throughput measurement module myself (the main benefit being that it doesnʼt require a manual multiplication at the end). Below you can find an excerpt, with some details like time/0 and msec/1 omitted for brevity:
defmodule ThroughputMeter do
use GenServer
def bump, do: GenServer.cast(__MODULE__, :bump)
def init(opts) do
state = %{
processed: 0,
interval: Keyword.get(opts, :interval, 50),
interval_start: time()
}
{:ok, state}
end
def handle_cast(:bump, state) do
{:noreply, state |> bump() |> measure()}
end
defp bump(state) do
%{state | processed: state.processed + 1}
end
defp measure(state) do
if rem(state.processed, state.interval) == 0 do
display(state)
%{state | interval_start: time()}
else
state
end
end
defp display(state) do
dt = time() - state.interval_start
ps = Float.round(state.interval / (msec(dt) / 1000), 2)
IO.puts("#{state.processed} processed, #{ps} jobs/sec")
end
end
The main benchmark function, not displayed here, first starts the above throughput meter and proceeds to spawn a number of worker processes that run the following trivial code (using the “long” input from above):
def print_and_notify_loop do
{:ok, _blob} = ChromicPDF.print_to_pdf({:html, @long_content})
ThroughputMeter.bump()
print_and_notify_loop()
end
Next, I ran the above benchmark with the same input for different numbers of workers, to see how the throughput would be affected by parallel execution. After leaving it running for a while, I measured the average PDFs generated per second and arrived at this data:
| Number of workers | PDF/s |
|---|---|
| 1 | 5.6 |
| 2 | 10.4 |
| 3 | 14.3 |
| 4 | 19.1 |
| 5 | 21.9 |
| 6 | 22.5 |
| 7 | 22.1 |
| 8 | 22.0 |
| 9 | 21.6 |
| 10 | 21.3 |
| 11 | 21.3 |
| 12 | 21.4 |
| 20 | 21.6 |
The first aspect to notice here is the 5.6 PDF/s throughput with only a single worker, which nicely lines up with the findings of Benchee in its benchmark and hence allows us to have some trust in these numbers. Next, the throughput is increased up to a factor of 4 when running more PDF rendering jobs in parallel, with the number of workers set to 6. Notably, it is not further increased by setting the number of workers to 7, 8, 10, or 20. As the number of CPUs in my work laptop is obviously limited, this was to be expected. The sweet spot seems to be around half the number of cores in the system, at least on my machine. Time to fix that hard-coded five!
Long-running process memory consumption
Another potential issue of the background Chrome process, brought to my attention by co-workers, is the likelihood of infinite growth of its memory usage. Prepared for the worst, I set out to measure Chromeʼs footprint while continously generating tons of PDFs.
Acquiring information about all your BEAMʼs external processes and their subprocesses is not a common problem to solve, so I used a shell command to collect memory usage information about all Chrome instances on my system. The information should be good enough to get an estimate about how quickly it grows.
# RSS column of ps
ps aux | grep Chrome | awk '{print $6};'
With the appartmentʼs heating switched off, I again started the parallel benchmark with the number of workers set to 5, and left for lunch. Perhaps 20 minutes and 24 thousand PDFs later, Chromeʼs memory usage had climbed from initially 700 MB to almost 8 GB.
50 processed, 23.61 jobs/sec
Chrome memory: 700092
100 processed, 25.43 jobs/sec
Chrome memory: 719748
150 processed, 24.53 jobs/sec
Chrome memory: 738304
200 processed, 24.9 jobs/sec
Chrome memory: 754464
250 processed, 23.39 jobs/sec
Chrome memory: 770572
[...]
1200 processed, 21.89 jobs/sec
Chrome memory: 1082428
1250 processed, 21.67 jobs/sec
Chrome memory: 1097152
1300 processed, 22.14 jobs/sec
Chrome memory: 1113008
1350 processed, 22.03 jobs/sec
Chrome memory: 1127800
1400 processed, 21.65 jobs/sec
Chrome memory: 1142496
[...]
23350 processed, 22.34 jobs/sec
Chrome memory: 8209100
23400 processed, 21.98 jobs/sec
Chrome memory: 8225128
23450 processed, 21.89 jobs/sec
Chrome memory: 8241112
23500 processed, 21.82 jobs/sec
Chrome memory: 8257252
23550 processed, 21.99 jobs/sec
Chrome memory: 8272504
An inevitable conclusion from this data: Chromeʼs memory footprint grows over time, and relatively fast. While I had expected some growth, it surprised me to see how the increase seems to be completely monotonic and uniform. Chrome apparently does not stop to return any freeʼd up memory to the system when navigating away from a page.
Usually memory consumption of a process is not a problem by itself. In the end, this is what memory is designed for, to be held by processes to speed up data access. 8 GB of memory usage after 24 thousand PDFs printed also does not seem like an awful lot, especially when at the same time the PDF throughput did not decline significantly. Besides, it is still possible (and in fact, likely) that Chrome will reuse or even release memory from its tab processes when available memory in the system is low. I just did not want to wait until my system would crawl to a halt under memory pressure.
Nevertheless, infinite growth in process memory usage commonly becomes an issue for long-running back-end applications that often requires operational countermeasures at some point. Whenever possible keeping memory growth under control it in the first place is by far preferable.
Hence, after discovering this, I committed a change to ChromicPDFʼs Session module to automatically restart its associated tab process after a configurable number of operations have been executed. By default, this number is set to 1000. Here is the 🎉 result:
4900 processed, 21.51 jobs/sec
Chrome memory: 2268748
4950 processed, 20.69 jobs/sec
Chrome memory: 2283932
5000 processed, 20.28 jobs/sec
Chrome memory: 1598792
5050 processed, 19.65 jobs/sec
Chrome memory: 748872
5100 processed, 21.22 jobs/sec
Chrome memory: 768076
Summing up
The benchmarks described in this article might have been rather naive and basic, but have shown that Chromeʼs PDF printing is considerably more performant when triggered from a running Chrome instance, in comparison to launching a new instance for every PDF print job. They also demonstrated how parallel print jobs can provide an additional performance gain, and what level of parallelism is still beneficial. Last, we have explored Chromeʼs memory consumption over time, and found a way to mitigate this issue.
Another potential issue some co-workers brought up is the security risk implied by re-using the same background browser process repeatedly, particularly regarding how data might be leaked between print jobs. While ChromicPDF already contains some mechanics to avoid leaking information (such as clearing the cookies after each job), any security concern obviously deserves close examination, which makes the topic a good candidate for a follow-up blog post.